Scheduling
Hat die Maximierung der CPU-Ausnutzung zu Ziel
- CPU-Burst: Prozess führt Instruktionen direkt auf der CPU aus
- häufig kurze Bursts, selten lange
- I/O-Bursts: Prozess wartet auf I/O-Event
CPU-Scheduling kann nur stattfinden, wenn ein Prozess:
- von running zu waiting wechselt
- von running zu ready wechselt (nur preemptive)
- von waiting zu ready wechselt (nur preemptive)
- terminiert
Scheduler
Der Scheduler bestimmt, welcher Prozess als nächstes die CPU nutzen darf. Man unterscheidet zwei Formen:
- Long-Term-Scheduler entscheidet, welche Prozesse in den Arbeitsspeicher geladen werden dürfen
- Short-Term-Scheduler entscheidet, welche Prozesse direkt auf der CPU ausgeführt werden können
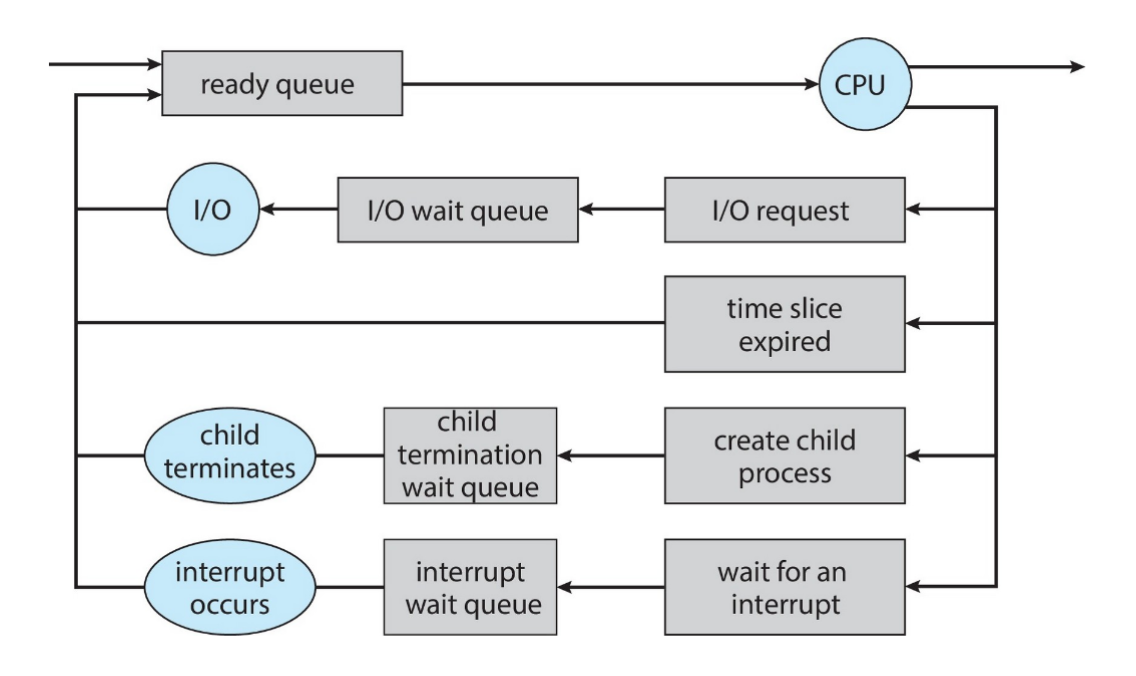
Er verwaltet dazu 2 Queues:
- Ready Queue: Prozesse, die im Hauptspeicher liegen und auf Ausführung warten
- Waiting Queue: Prozesse, die auf ein Event (z.B. I/O) warten
Kooperativ
Beim kooperativen Scheduling gibt ein Prozess, sollte er fertig sein oder auf etwas warten, die CPU freiwillig für andere Prozesse frei
- einzelner Prozess kann System blockieren
Präemptiv
Beim präemptiven Scheduling kann das Betriebsystem einem Prozess die CPU zwangsweise entziehen
- faire Aufteilung der CPU-Zeit möglich
- stabiler, aber aufwändiger zu implementieren
Echtzeit-Scheduling
Bei Echtzeit(-Scheduling) geht es darum, dass Aufgaben innerhalb eines festen Zeitraums erledigt werden müssen
- harte Echtzeit: Einhaltung von Deadlines wird garantiert
- z.B. verwendet bei Sensorik selbstfahrender Autos (Gefährdung von Menschenleben)
- weiche Echtzeit: Deadines sollten zwar eingehalten werden, allerdings ist ein geringes Überschreiten dieser nicht problematisch.
- z.B. Computerspiele (Framerate, Verzögerung verschlechtert Spielergebnis, aber ist akzeptabel)
Das Echtzeit-Scheduling wird durch zwei Formen von Latenz erschwert:
- Interrupt Latency: Zeit, die zwischen dem Eintreffen eines Interrupts und dem Ausführen der Service Routine vergeht
- Dispatch Latency: Zeit, die benötigt wird, um den aktuelle laufenden Prozess zu stoppen und den neuen zu starten (inkl. niedrig-prioritäte Prozesse, die Ressourcen freigeben müssen)
Anforderungen an Echtzeit-Scheduling-Verfahren
Ein echtzeitfähiges Scheduling-Verfahren muss sicherstellen, dass Prozesse innerhalb ihrer festgelegten Zeit ausgeführt werden. Dazu sollte es:
- die Startzeit eines Prozesses an seine Deadline anpassen können
- Prozesse mit kürzeren Deadlines bevorzugen können
- periodische Prozesse, die regelmäßig innerhalb derselben Deadline ausgeführt werden müssen, verwalten können
- Rate Monotonic Scheduling: Jeder Prozess erhält eine Priorität, die invers zu seiner Perioden-Länge ist
- Problem: Prozesse mit hoher Priorität können andere unnötig am Einhalten ihrer Deadline hindern
- Earliest Deadline First Scheduling (EDF): Je früher die Deadline, desto höher die Priorität
- Proportional Share Scheduling: Anteile an der CPU-Laufzeit werden unter allen Prozessen verteilt
- Rate Monotonic Scheduling: Jeder Prozess erhält eine Priorität, die invers zu seiner Perioden-Länge ist
- insbesondere auch präemptiv sein
Scheduling-Algorithmen
Kriterien für Scheduling-Algorithmen
- CPU-Ausnutzung maximieren
- Throughput / Durchsatz: Anzahl der Prozesse, die in einer Zeiteinheit fertig werden
- Turnaround time: Zeit, die es braucht, einen spezifischen Prozess auszuführen
- Waiting time: Zeit, die ein Prozess in der ready queue verbringt
- Response time: Zeit, die vergeht, bis ein Prozess das erste Mal ausgeführt wird
Beispiel
| Thread ID | Startzeit | Ausführungszeit | Priorität |
|---|---|---|---|
| 1 | 0 | 8 | 9 |
| 2 | 2 | 6 | 11 |
| 3 | 2 | 6 | 10 |
| 4 | 4 | 10 | 11 |
- Quantum-Länge = 3
First-Come, First-Served / FiFo
| Thread ID | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | R | R | R | R | R | R | R | R | ||||||||||||||||||||||
| 2 | - | - | - | - | - | - | R | R | R | R | R | R | ||||||||||||||||||
| 3 | - | - | - | - | - | - | - | - | - | - | - | - | R | R | R | R | R | R | ||||||||||||
| 4 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | R | R | R | R | R | R | R | R | R | R |
- Convoy effect: Kurze Prozesse (I/O-bound) können lange hinter langen Prozessen (CPU-bound) hängen
Round-Robin
- Jeder Prozess erhält ein Zeitquantum , nachdem er unterbrochen wird, sofern er nicht bereits terminiert ist
- Durchsatz geringer als bei FCFS, wenn der overhead für Kontext-Wechsel hinzugerechnet wird
Quantum
Ein Quantum ist eine kleine Zeiteinheit von typischerweise bis Millisekunden.
- Schranke für die zusammenhängende CPU-Zeit eines Prozesses
- bei prioritätenlosem Scheduling (Round-Robin): Prozesse und Quantum jeder Prozess wartet maximal Zeiteinheiten, bis er das nächste Mal ein Quantum zugewiesen bekommt
- großes Quantum FiFo
- kleines Quantum viele Kontextwechsel (Zeitverlust)
- Quantum wird meist so gewählt, dass ca. der Prozesse in einem Quantum fertig werden
Prioritätsloser RR
| Thread ID | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | R | R | R | - | - | - | - | - | - | R | R | R | - | - | - | - | - | - | - | - | - | R | R | |||||||
| 2 | - | R | R | R | - | - | - | - | - | - | - | - | - | R | R | R | ||||||||||||||
| 3 | - | - | - | - | R | R | R | - | - | - | - | - | - | - | - | - | R | R | R | |||||||||||
| 4 | - | - | - | - | - | - | - | - | R | R | R | - | - | - | - | - | - | - | - | R | R | R | R | R | R | R |
Prioritätenbasierter RR
- Beim Priority Scheduling werden Prozesse mit höherer Priorität zuerst ausgeführt
- bei gleichen Prioritäten wird Round Robin angewandt
- kann allerdings zu Starvation führen
| Thread ID | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | R | R | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | R | R | R | R | R | R |
| 2 | R | R | R | - | - | - | R | R | R | |||||||||||||||||||||
| 3 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | R | R | R | R | R | R | ||||||||
| 4 | - | R | R | R | - | - | - | R | R | R | R | R | R | R |
Shortest Job First
- SJF ist optimal in Bezug auf durchschnittliche Wartezeit (Gegenteil vom Convoy effect)
- präemptive Variante heißt Shortest Remaining Time First
- SJF ist eine Variante von prioritätenbasiertem Scheduling, wobei die Priorität invers zur nächsten CPU-Burst-Dauer ist
- Länge des nächsten CPU-Burst muss jeweils geschätzt werden:
- Es sei die tatsächliche Länge des -ten CPU-Bursts, die geschätzte Länge des -ten CPU-Bursts und (oft ). Dann schätzen wir mittels:
Starvation Avoidance
Moderne Betriebssysteme verwenden verschiedene Fairness-Algorithmen, um auch Threads mit niedriger Priorität regelmäßig CPU-Zeit zuzuweisen. Zentraler Bestandteil solcher Fairness-Algorithmen sind häufig:
- Tracken der Wartezeiten der zur Ausführung bereiten Threads
- dynamische Anpassen der Thread-Prioritäten
- häufig ausgeführte Threads: Priorität wird verringert
- selten ausgeführte Threads: Priorität wird erhöht, um Starvation zu vermeiden (Aging)
- Boosting: Belohnung für langes Warten, z.B. auf I/O-Event (Windows)
Multilevel-Queue Scheduler
Ein Multilevel-Queue Scheduler teilt Prozesse in verschiedene Priority-Queues auf, abhängig von Priorität und Aufgabe
- Jede Priority-Queue hat ihr eigenes Vorgehen und ihre eigenen Regeln für das Scheduling
- Auch die Auswahl der zu bearbeitenden Queue kann mittels Scheduling-Verfahren definiert werden
- Multilevel-Feedback-Queue: ein Prozesse kann zwischen den verschiedene Queues wechseln, z.B. hilfreich für die Implementierung von Aging
Bewertung von Algorithmen
- Deterministic Model: Berechnet die Effizienz basierend auf einer vordefinierten Workload
- Queuing Model: Computer wird als Menge von Queues modelliert und stochastische Wahrscheinlichkeiten für Ankunftszeiten und Burst-Zeiten angenommen
- Little’s Formula: Es sei die durchschnittliche Queue-Länge, die durchschnittliche Wartezeit in einer Queue und die durchschnittliche Ankunftsrate in einer Queue. Nach Little’s law muss nun die Anzahl der eintreffenden Prozesse gleich der abgeschlossenen sein (steady state):
- Simulation: Programmiertes Modell eines echten Computers, auf dem Workloads ausgeführt und ausgewertet werden (Zufallszahlgeneratoren, stochastische Verteilungen oder Trace Tapes aus echtem System)
- Implementation: Neuer Scheduler wird schlicht implementiert und getestet
- hohe Kosten, hohes Risiko, wechselnde Verwendung
- flexible Scheduler können in jedem System anders konfiguriert oder per API modifiziert werden

Thread Scheduling
Sofern Threads unterstützt werden, werden diese anstelle von Prozessen gescheduled
- System contention scope (SCS): Kernel Threads werden direkt auf die CPU gescheduled und konkurrieren gegeneinander
- Process contention scope (PCS): Bei Many-to-one und Many-to-may Modellen muss die Thread-Bibliothek entscheiden, welcher Thread dem laufenden Kernel-Thread zugeordnet wird
- häufig werden programmatisch gesetzte Prioritäten verwendet
Multiple-Processor Scheduling
- Symmetric multiprocessing (SMP): Jeder Prozessor ist für eigenes Scheduling verantwortlich (gemeinsame ready Queue, private run Queue je Kern)
- wenn jeder Kern mehrere Threads hält, kann er bei einem memory stall schnell wechseln | Chip-multithreading (CMT) wenn jeder Kern 2 Threads (hardware threads) hält, sind logisch doppelt so viele Kerne sichtbar
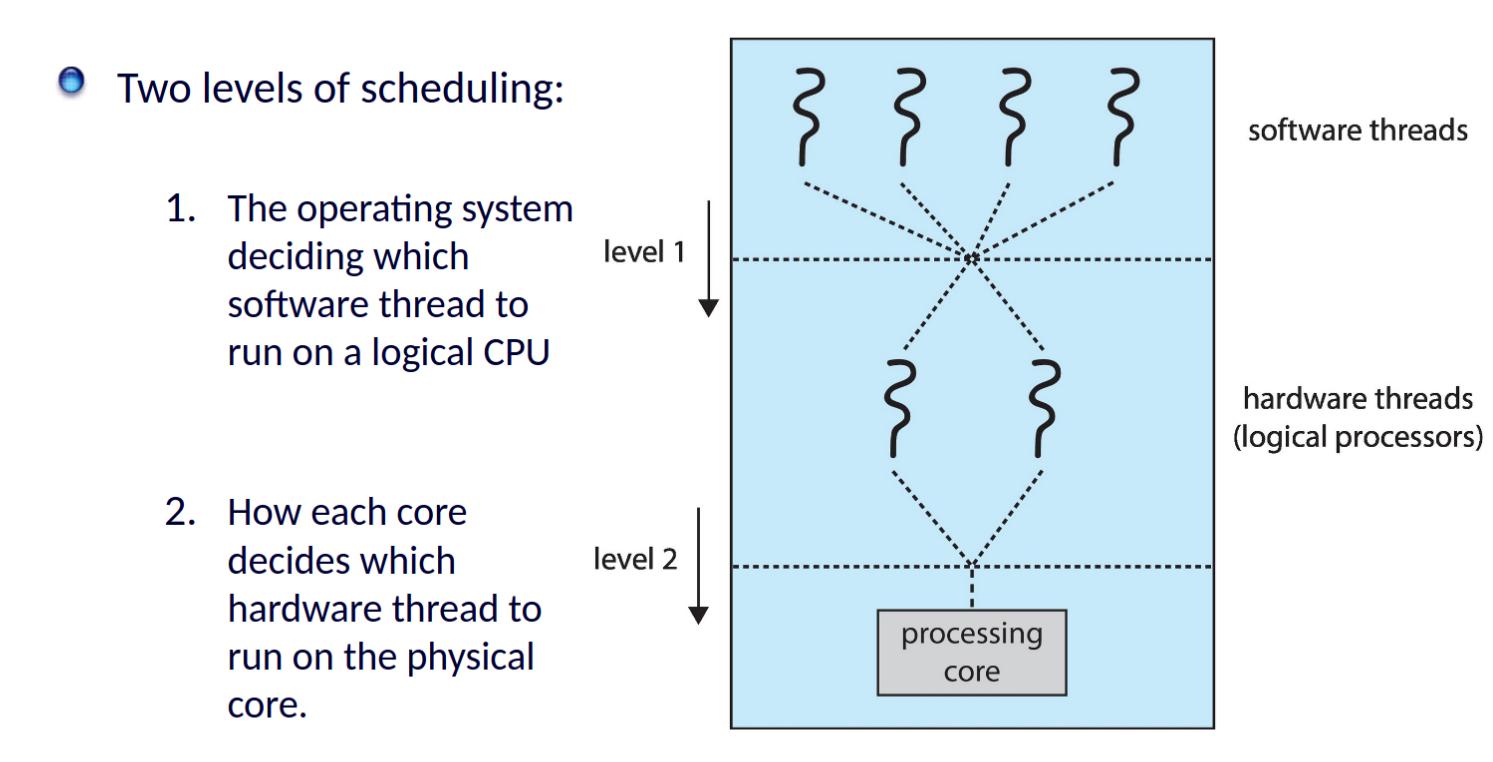
- Load Balancing: Alle CPUs sollten bestmöglich ausgelastet werden
- Push migration: Periodischer Prozess prüft die Auslastung der Kerne und schiebt ggf. Threads zu einem weniger ausgelasteten Kern
- Pull migration: Kern im Leerlauf zieht sich selbst einen Thread von einem anderen Kern
- Processor Affinitiy: Ein Thread, der einmal auf einem Prozessor gelaufen ist, hat sich dort bereits Caches befüllt
- Load Balancing könnte damit zu weniger effizienten Ausführung führen
- Soft affinity: OS versucht den Thread auf dem selben Prozessor zu halten, garantiert es aber nicht
- Hard affinity: Prozess / Thread darf einen Satz an Prozessoren auswählen, auf dem er laufen darf
- NUMA: Wenn das OS NUMA-aware ist, wird des versuchen, Speicher nahe an dem jeweiligen Prozessor zuzuweisen
Dispatcher
Kontext-Wechsel
CPU schaltet von einem Prozess auf einen anderen um:
- Kontext (gesamter, aktueller Zustand) des aktuellen Prozess im PCB speichern
- Kontext des neuen Prozesses laden, welcher vom Scheduler ausgewählt wurde
- Fortsetzung der Programmausführung im User-Mode am aktuellen Programm-Counter
Dispatch-Latency: Zeit zwischen dem Stoppen des einen uns Starten des anderen Prozesses
Praxis
Linux
Bis Version 2.5
- Präemptiv, Prioritäten-basiert,
- Real-time: 0 bis 99
- Time-Sharing: 100 bis 140 (Niceness: -20 bis 19)
- längeres Quantum für höhere Prioritäten
- Jede Task ist active (lauffähig), bis ihr Quantum aufgebraucht ist
- wird erst wieder aufgefüllt, wenn alle Tasks expired (Quantum abgelaufen) sind
- implementiert über zwei priority arrays
- Hat gut funktioniert, aber schlechte Antwortzeit für interaktive Prozesse
Ab Version 2.6.23 (CFS)
Im Gegensatz dazu gibt es beim Completely Fair Scheduler keine festen Prioritäten, sondern jedem Prozess wird eine gewisse, fair-verteilte Menge an CPU-Zeit zugewiesen, die proportional zu seinen Anforderungen sein soll. Dabei werden zwei Typen von Prozessen unterschieden:
- interaktive Prozesse: benötigen häufig CPU-Zeit, um schnell reagieren zu können
- rechenintensive Prozesse: benötigen weniger häufig, dafür aber mehr CPU-Zeit
Weiterhin:
- Real-time: 0 bis 99
- Time-Sharing: 100 bis 140 (Niceness: -20 bis 19)
Virtual run time:
- je Task wird eine
vruntime-Variable geführt, die speichert, wie lange der Prozess bereits gelaufen ist- je niedriger die Priorität, desto höher die Verfallsrate (echte Laufzeit virtuelle Laufzeit)
- bei default Priorität: echte Laufzeit virtuelle Laufzeit
- Scheduler wählt Task mit niedrigster virtueller Laufzeit in höchster Klasse (real-time, time-sharing) aus
Zudem:
- unterstützt Load Balancing, ist aber auch NUMA-aware
Windows
- präemptiv, Prioritäten-basiert
- Variable class: 1 - 15
- Memory Management Thread auf 0
- Real-time class: 16 - 31
- Eine Queue je Priorität
- Boosting: nach langem Warten sowie 3x für Fenster im Vordergrund
- kein zentraler Scheduler, stattdessen werden Scheduling Routinen aufgerufen, wann immer sich der ready state eines Threads ändert
- event driven keine harte Echtzeit
