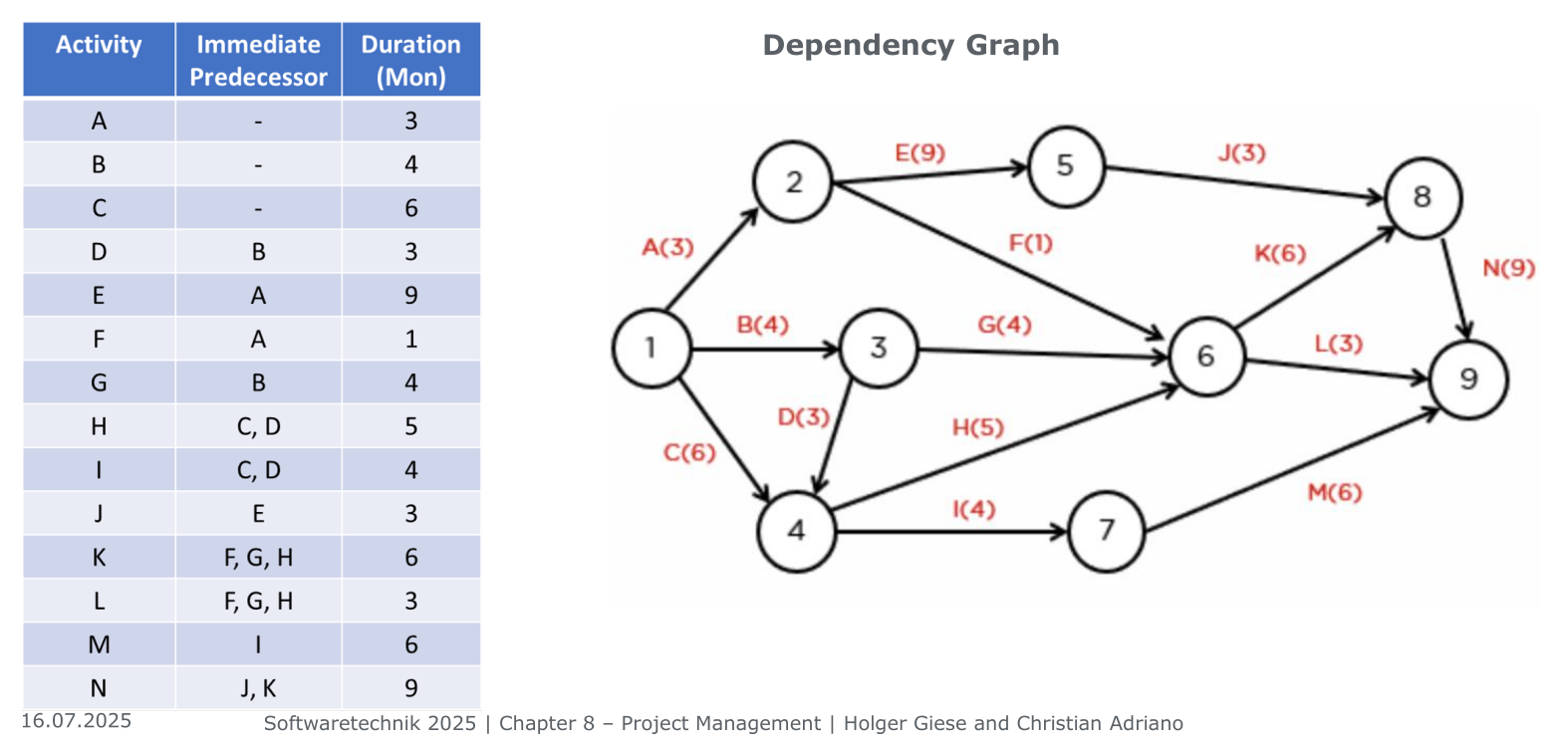
Time Management – Critical Path Method (CPM)
Critical path longest sequence of necessary activities diameter of the graph
Pros & Cons
Advantages:
- Effective communication
- Easier prioritization of tasks
- More precise planning
- Better visualization
Disadvantages:
- Multiple complexities
- Limited applicability
- Less understanding of resources
Definitions
- : earliest start time
- : latest start time
- : earliest completion time
- : latest completion time
- : cost of task (represented as edges)
- Float: how long can a task be postponed without affecting its task order or the project timeline
- Critical path has no float
- Total float: amount of time a task can be postponed (w.r.t. the earliest start time) without delaying the project
- Free float: amount of time a task can be postponed without pushing back the earliest start time of a succeeding task
Calculations
Forward Pass: with preceding
Backward Pass: with preceding
Critical Path:
- for all nodes on the path
- for all neighbors and
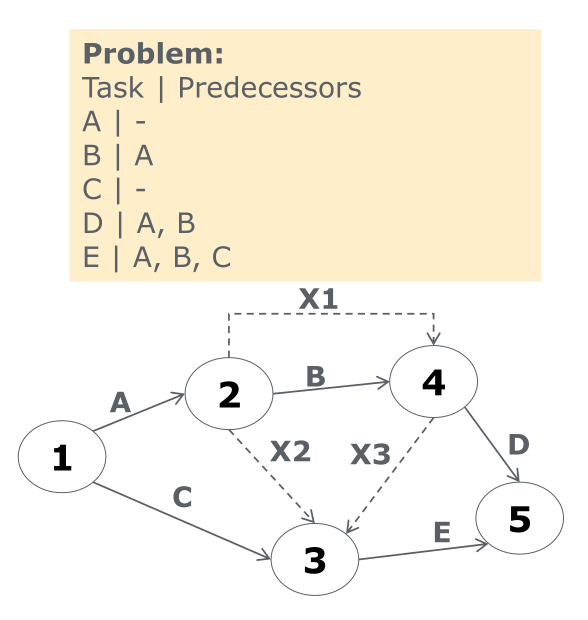
Dummy Task: Edges without cost (labeled ), that can be used to model otherwise inexpressible dependencies
Project Management Anti-Patterns
- Analysis Paralysis: Striving for perfection and completeness in the analysis phase often leads to project gridlock and excessive trashing of requirement methods
- Death by Planning: Excessive planning for software projects leads to complex schedules that cause downstream problems
- Irrational Management: Habitual indecisiveness and other bad management habits lead to de facto decisions and chronic development crises
- Fire Drill: Airline pilots describe flying as hours of boredom followed by 15 seconds of sheer terror. Many software projects might resemble that, when suddenly urgent demands for new requirements imply large refactoring
Scrum
Mythical Man-Month
Adding more people to a late project makes it later — Fred Brooks
Reasons:
- training newcomers
- knowledge acquisition
- more communication
- more coordination
- more planning to partition work
- more interfaces, more integration
Risk Management
Unter einem Risiko ist ein eventuelles, hinsichtlich seiner Eintrittswahrscheinlichkeit und Auswirkung bewertetes, zukünftiges Ereignis zu verstehen
Goal: Increase the probability and/or impact of positive risks and decrease the probability and/or impact of negative risks, in order to optimize the chances of project success
Process
- Plan Risk Management: definition of activities and tools
- Identify Risks: study the specific risks of the project
- Perform Qualitative Risk Analysis: prioritize risks for further analysis
- Perform Quantitative Risk Analysis: analyze the probabilities and impacts of risks
- Plan Risk Response: develop options, strategies, and actions to mitigate risks
- Implement Risk Response: execute the risk response
- Monitor Risks: tracking identified risks, analyze new risks, and evaluate risk process effectivity
Categories
- Technical risk: scope definition, requirements, estimates, assumptions, technical process, technology, technical interfaces, etc.
- Management risks: poor allocation of time and resources, funding, lack of prioritization of projects, inadequate quality of the project plan, poor use of project management disciplines (e.g. communication), etc.
- Commercial risks: contractual terms and conditions, internal procurement, suppliers, vendors, subcontracts, client / customer stability, partnership / join-ventures, etc.
- External risks: legislation, exchange rates, sites / facilities, environmental / weather, competition, regulatory, etc.
Qualification
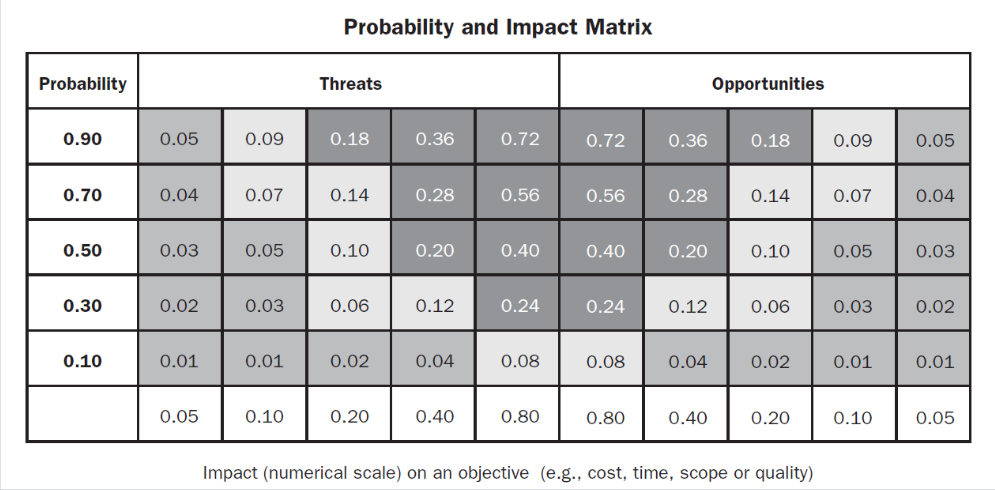
Organization’s thresholds for low, moderate, or high risks are used to categorize the risks
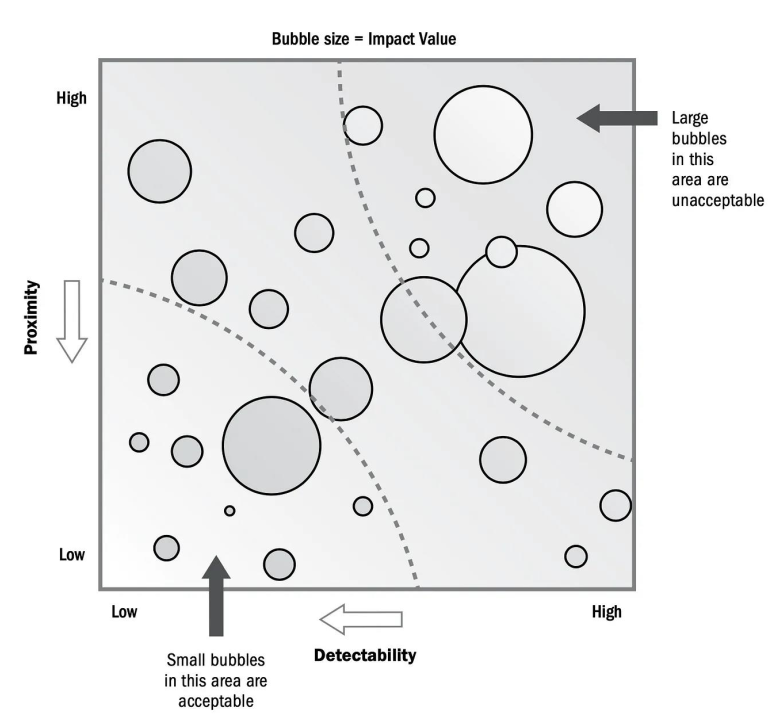
Additional Parameter:
- Urgency: the period of time within which a response to the risk is to be implemented
- Proximity: the period of time before the risk might have an impact on one or more objectives
- Dormancy: the period of time that may elapse after a risk has occurred before its impact is discovered
- Manageability: the ease with which the risk owner can manage the occurrence or impact of risk
- Controllability: the degree with which the risk owner is able to control the risk’s outcome
- Detectability: the ease of which the results of the risk occurring (or about to occur) can be detected and recognized
- Connectivity: the extent to which the risk might have a positive or negative effect on the organization’s strategic goals
- Propinquity: the degree to which a risk is perceived to matter by one or more stakeholders
Each of these parameters can be combined in charts to be analyzed in 2 or more dimensions:
Response Strategies
Negative Risks:
- Avoid: Eliminate risks by clarifying requirements, obtaining information, improving communication, acquiring expertise, developing proof-of-concepts, etc.
- Transfer: Acquire insurance, delegate objective associated with the risk to another team, postpone objective, etc.
- Mitigate: Reduce the probability of occurrence and/or impact by designing fail-safe mechanisms, developing safety features, adding specific regression tests, training team and operators, etc.
- Accept: No change or response action is needed, either because the occurrence or impact are negligible
Positive Risks:
- Exploit: Eliminate the uncertainty to increase the chances that the opportunity happens, e.g. obtaining the best resources for the team / project
- Share: Create the conditions that a third-party also benefits of the opportunity, e.g. establish agreements for how the project outcomes will be shared
- Enhance: Increase the probability and impact of a given risk, e.g. adapting the plan so an activity finishes earlier than initially planned
- Accept: No change or response action is needed, just be willing to take advantage of an opportunity if it happens
Cost Management
Costs of a project is composed of the costs of the team, software licenses, hardware, facilities, financial costs (loan interests), etc.
Value of a project consists of the benefit perceived by the customer of the final product
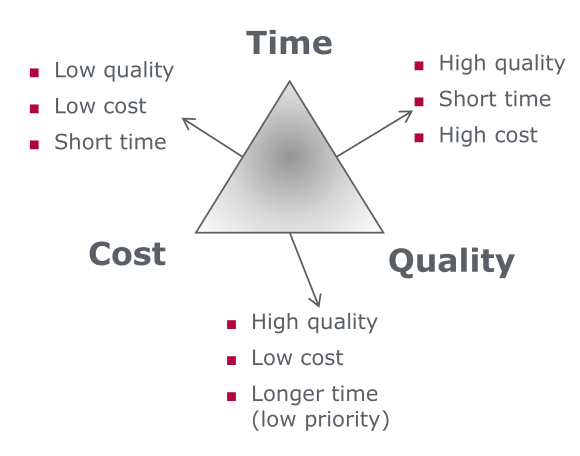
Triangle of Constraints:
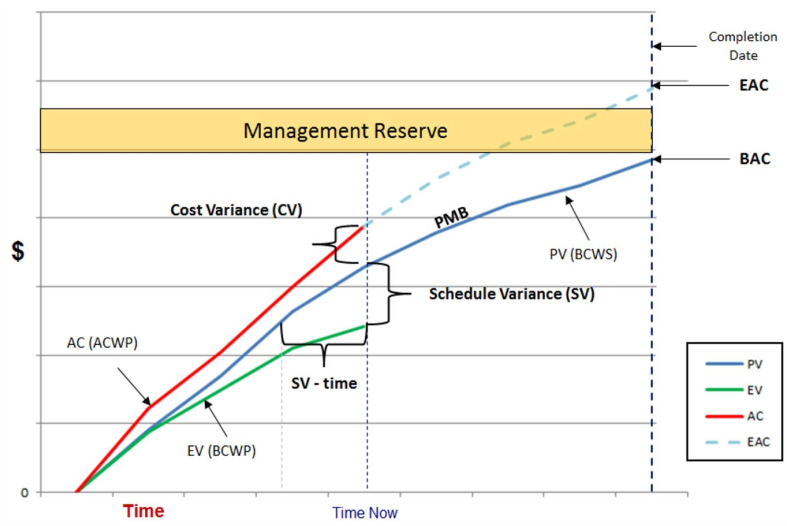
Earned Value Analysis
- Earned value
- Planned value:
- Actual cost:
- Budget at completion
- Cost variance
- Cost performance index
- good (under budget) | bad (over budget) | (as planned)
- Estimate at completion
- Optimist:
- Pessimist:
- Estimate to complete
- To-complete performance index:
- | performance required to achieve original
- | performance required to achieve a new, revised budget total
- Independent estimate at completion (manager’s, no team input)
Operations – Grundlagen
Operations / Betrieb: Routinemäßige Ausführung und Management einer Aktivität, eines Produkts, Service oder eines anderen Configuration Item
IT Service: Ein Service, der auf dem Einsatz von Informationstechnologie basiert
IT Service Management (ITSM): Bezeichnet die Fähigkeiten und Prozesse zur Zuweisung und Steuerung der Aktivitäten und Ressourcen einer Organisation für die Planung, Entwurf, Transition, Lieferung und Verbesserung von IT-Services
Information Technology Infrastructure Library (ITIL)
Best-Practice-Leitfaden für das IT Service Management
ITIL-4 Praktiken
- Availability Management: sicherstellen, dass Services den vereinbarten Verfügbarkeits-Leveln entsprechen, um die Bedürfnisse der Kunden und Benutzer zu erfüllen
- Capacity and Performance Management: sicherstellen, dass Services die vereinbarte und erwartete Leistung erbringen sowie den aktuellen und zukünftigen Bedarf kosteneffizient erfüllen
- Change Enablement: Anzahl an erfolgreichen Changes an Services und Produkten maximinieren
- Risikobewertung, Autorisierung und Planung von Changes (Change-Kalender)
- Incident Management: negative Auswirkungen von Incidents so gering wie möglich halten, indem der normale Service-Betrieb so schnell wie möglich wiederhergestellt wird
- Zusammenarbeit unterschiedlicher Stakeholder: Service-Desk, IT-Support, Zulieferer, Kunden
- Monitoring and Event Management: Service oder Service-Komponenten systematisch überwachen und Zustandsänderungen (Events) aufzeichnen und melden
- identifiziert und priorisiert Infrastruktur-, Service-, Geschäftsprozess- und Information-Security-Events
- legt entsprechende Reaktionen fest (z.B. informierend, warnend, Ausnahme)
- Problem Management: Eintrittswahrscheinlichkeit und Auswirkungen von Incidents reduzieren, indem aktuelle und potentielle Ursachen identifiziert sowie Workarounds und Known Errors entwickelt werden
- Problem: aktuelle oder potentielle Ursache eines oder mehrerer Incidents
- Known Error: Problem, welches zwar analysiert, aber noch nicht gelöst wurde
- Workaround: vorläufige Lösung, welche die Auswirkungen eines Incidents reduziert und neutralisiert, solange keine vollständige Lösung zur Verfügung steht
- Release Management: neue und geänderte Services oder Funktionen zur Verfügung stellen
- Service Configuration Management: sicherstellen, dass präzise und belastbare Informationen über die Konfiguration der Services vorliegen
- Service Continuity Management: sicherstellen, dass im Katastrophenfall (Desaster) dier Verfügbarkeit und Leistung eins Service auf einem ausreichenden Level erhalten bleibt
- Schutz der Interessen der Stakeholder, Unternehmensreputation, Marke und wertschaffender Aktivitäten
- Service Desk: Nachfrage nach Lösungen von Incidents und Service Requests erfassen
- Single Point of Contact (SPCO) des Service Provider für alle Anwender
- Service Validation and Testing: sicherstellen, dass neue und geänderte Produkte und Services die definierten Anforderungen erfüllen
- Mehrwert abhängig von Input der Kunden, Geschäftsziele und regulatorischen Anforderungen Qualitäts- und Performance-Indikatoren
- Deployment Management: neue oder geänderte Hardware, Software, Dokumentation, Prozesse oder andere Komponenten in eine Live-Umgebung transferieren
- ggf. auch Bereitstellung von Test- und Staging-Umgebungen
- Infrastructure and Platform Management: Infrastruktur und Plattformen, die von der Organisation genutzt werden, betreuen und überwachen
- Monitoring der in der Organisation verfügbaren technischen Lösungen (inklusive externer Service Provider)
- Software Development and Management: sicherstellen, dass Anwendungen die Bedürfnisse der internen und externen Stakeholder hinsichtlich Funktionalität, Zuverlässigkeit, Wartbarkeit, Compliance und Auditierbarkeit erfüllen
Kann bei Spezialisierung des Personal auf Aktivitäten / Praktiken durch Entkopplung von der Entwicklung zu vielen Silos für die speziellen Aktivitäten / Praktiken führen
DevOps
Agile Entwicklung (Dev) und Betrieb (Ops) zusammen denken
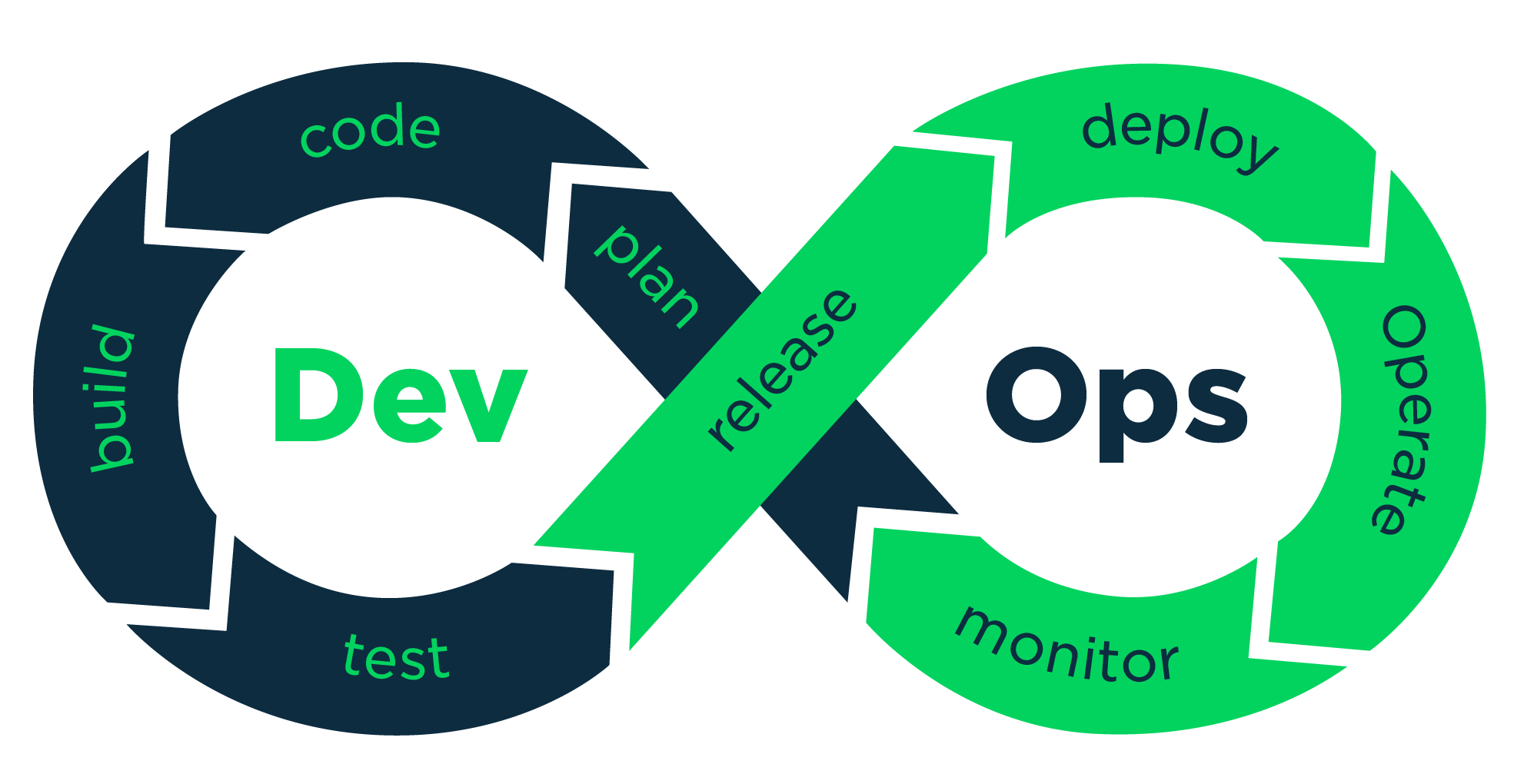
Hintergrund
- Entwicklung muss sehr schnell auf veränderte Wettbewerbssituation reagieren
- Operations muss stabile, zuverlässige und sichere Services für den Kunden bieten
- diametral entgegengesetzte Ziele
- oft Abwärtsspirale bei Time to Market und Qualität, häufige Ausfälle, wachsende technische Schulden
DevOps-Idee:
- kleine Entwicklerteams implementieren unabhängig voneinander ihre Features
- Code-Deployments der Teams sind Routinen und werden zu den normalen Arbeitszeiten ausgeführt
- durch schnelle Feedback-Schleifen für jeden Prozessschritt kann jeder sofort die Ergebnisse seiner Aktivität sehen
- führt bei leistungsstarken Firmen zu höheren Metriken bei Durchsatz, Zuverlässigkeit und Firmenperformance
Skalierbarkeit durch DevOps
- Klassisch: Hinzufügen von neuen Entwicklern zum Erreichen einer Deadline drückt die Gesamtproduktivität
- DevOps: Bei der richtigen Architektur, den richtigen technischen Praktiken und den richtigen kulturellen Normen können kleine Teams mit Entwicklern schnell, zuverlässig und unabhängig voneinander Änderungen für die Produktivumgebung entwickeln, integrieren, testen und deployen
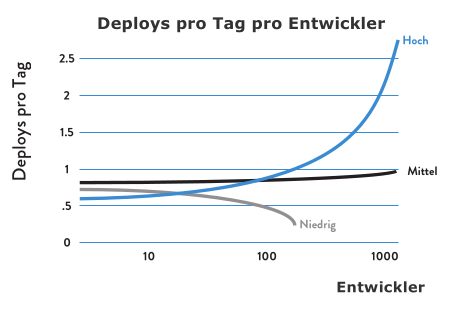
- Niedrige Entwickler-Performance: weniger Deploys bei wachsender Teamgröße
- Mittlere Entwickler-Performance: gleichbleibende Deploy-Anzahl
- Hohe Entwickler-Performance: lineares Wachstum
Wertketten
Folge von Aktivitäten, die erforderlich sind, um eine Ware / einen Service für einen Kunden zu entwerfen, zu produzieren und auszuliefern
Kennzahlen:
- Durchlaufzeit (lean time): von “Ticket angelegt” bis “Arbeit abgeschlossen”
- Verarbeitungszeit (touch time): von “Arbeit beginnt” bis “Arbeit abgeschlossen”
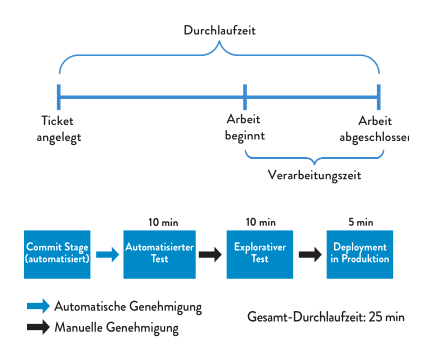
Prinzipien des DevOps
Prinzipien des Flow: das Ausliefern von Arbeit von der Entwicklung über Operations hin zu unseren Kunden beschleunigen
- z.B. produktivähnliche Umgebungen für Entwickler, schnelles und automatisiertes Testen, Continuous Integration, Continuous Delivery, einfache Rollbacks (Risiko reduzieren)
Prinzipien des Feedbacks: durch schnelles und kontinuierliches Feedback bei allen Schritten unserer Wertkette schaffen oder hinterlassen wir dort Wissen, wo es gebraucht wird
- z.B. Telemetrie- / Loggingdaten sammeln und analysieren, Arbeit in der Wertkette beobachten, A/B-Tests für Hypothesen, Peer Review / Pair Programming
Prinzipien des kontinuierlichen Lernens und Experimentierens: eine Kultur des Vertrauens und ein wissenschaftlicher Ansatz, der das Eingehen von Risiken unterstützt und das firmenweite Lernen ermöglicht
- z.B. Kultur des Lernens, Post-Mortem-Meetings (nach Unfällen) ohne Schuldzuweisungen, Zwischenfälle an Game Days üben, kalkulierte Risiken unterstützen, Wissen in Chatrooms und Bots sammeln, gemeinsames Repository für gesamte Firma, Zeit für Lernen und Verbesserungen reservieren (Rituale, Meetings, Workshops, Community-Strukturen)
Continuous Delivery, Continuous Deplyoment
- Continuous Delivery: kurzlebige Feature-Branches, die regelmäßig in einen releasebaren Trunk eingecheckt werden
- Continuous Deployment: mindestens einmal pro Tag oder automatisch nach jeder Änderung werden gute Builds deployed