Virtual Memory
- logische / virtuelle Adressen: Adressen, die von der CPU generiert werden
- physische Adressen: Adressen, die tatsächlich auf den Hauptspeicher zeigen
- logische und physische Adressen sind zur Compile- und Load-time identisch, sie unterscheiden sich erst zur Execution-time
Diese Unterscheidung ermöglicht es,
- jedem Prozess seinen eigenen virtuellen Speicherraum zu geben auf den die anderen Prozesse nicht zugreifen können und
- insgesamt mehr Speicher adressierbar zu machen, als physisch verfügbar ist
Multistep-Processing
Die Addressbindung kann zu drei verschiedenen Zeitpunkten stattfinden:
- Compile time: Startadresse muss a priori bekannt sein Programm muss bei Änderung der Startadresse neu kompliliert werden
- Load time: Der vom Compiler generierte Code muss verschiebbar sein
- Execution time: Adressbindung wird bis zur Ausführung verschoben, das Programm kann also auch während der Ausführung verschoben werden
- benötigt Hardware-Unterstützung (z.B. base- und limit-Register)
Dynamic Linking
- Static linking: (System-)Bibliotheken werden bereits vom Compiler bzw. Loader in die ausführbare Datei eingebunnden
- Dynamic linking: es wird nur ein Funktionsrumpf (stub) eingebunden, der sich dann zur Laufzeit durch die eigentliche Bibliothek ersetzt
Dynamic Loading
Es wird nicht das gesamte Programm in den Speicher geladen, sondern nur die sofort benötigten Routinen
- weitere Routinen werden bei Aufruf nachgeladen
Memory Management Unit (MMU)
Die Memory Management Unit (MMU) ist eine Hardware-Komponente, die zur Laufzeit virtuelle Adressen in physische Adressen übersetzt. Einfache Ansätze hierfür sind:
- Base- und limit-Register: Speicherzugriff wird gegen diese Register geprüft und ggf. blockiert
- Relocation- und limit-Register: Jeder Speicherzugriff wird gegen das limit-Register geprüft und anschließend das relocation-Register zur logischen Adresse addiert
Segmentierung (veraltet)
Bei der Segmentierung werden die Speicherbereiche eines Prozesses in Abschnitte unterteilt
- z.B. Daten, Programm, Stack, Heap
- jedes Segment erhält Basisadresse und Länge
- MMU addiert auf die jeweilige Basisadresse und prüft, ob die physische Adresse im zugewiesenen Speicher liegt
- es entsteht externe Fragmentierung durch Lücken zwischen Segmenten
- Auswahl-Strategien bei neuer Anfrage: first-fit, best-fit und worst-fit
- kann durch compaction wieder behoben werden
- Segmente können nicht beliebig wachsen ohne verschoben werden zu müssen
Paging (aktuell)
Beim Paging wird der physische Speicher in gleich-große Frames und der virtuelle Speicher in Pages der gleichen Größe unterteilt.
- Pages laufender Prozesse werden in den Hauptspeicher geladen
- Adresse besteht auf Page-Nummer und Offset
- durch feste Größe der Pages entsteht keine externe, aber ggf. interne Fragmentierung
- in 64-Bit Systemen ist der virtuelle Speicher deutlich größer als der physische Speicher wodurch die Seitentabellen sehr groß werden können
Page-Table
Speichert Basisadressen zu den jeweiligen Page-Nummern sowie weitere Status-Bits je Eintrag:
- Reference-Bit: wird gesetzt wenn die Page bereits verwendet wurde
- Dirty-Bit: wird gesetzt, wenn der Page-Inhalt modifiziert wurde
- Valid-Bit: wird gesetzt, wenn für eine Page das passende Frame im Hauptspeicher geladen ist (bzw. ob der Zugriff legal ist)
- Weitere Bits für Lese-, Schreib- und Execute-Zugriffe sind möglich
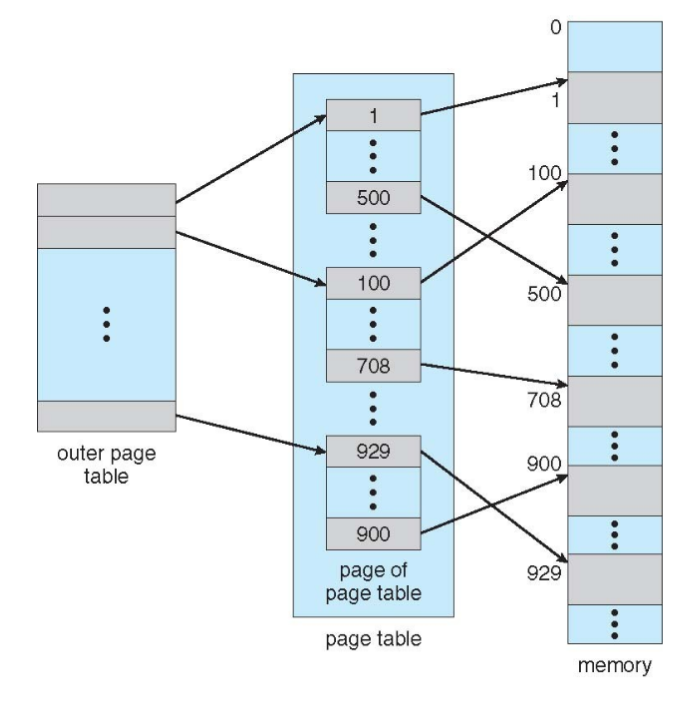
Hierarchical Page Table
Bei mehrstufigen Page-Tabellen wird die Page-Nummer wiederholt unterteilt
- Large Page-Bit: gibt an, dass bspw. 4MB statt den typischen 4KB Seitengröße verwendet wurde
- dazu wird letzte Page-Table-Ebene ausgelassen
Hashed Page Table
Die Page-Nummer wird gehasht und zeigt dann auf einen Eintrag in der Page-Table
- der Eintrag besteht dann aus einer Liste aller Pages, die auf ihn mappen
- wird häufig in Adressbereichen Bit verwendet und ist besonders dann hilfreich, wenn der Adressraum nur spärlich (sparse) belegt ist
Inverted Page Table
Anstelle von den möglichen logischen Pages werden nur die tatsächlich physisch vorhanden Pages eingetragen
- Zugriff erfolgt über Suche, kann aber mittels hash table und TLB beschleunigt werden
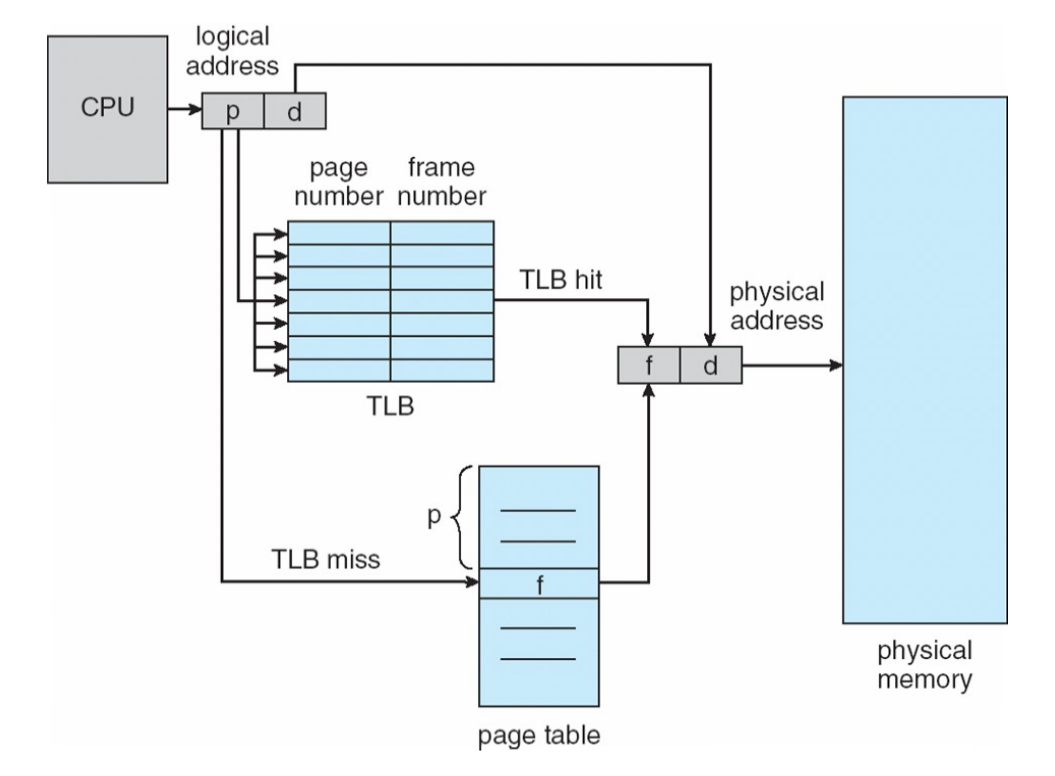
Transition Lookaside Buffer (TLB)
Die Übersetzung von virtuellen in physische Adressen kann viel Zeit in Anspruch nehmen, da man für jede Übersetzung in der Page-Table im Hauptspeicher nachschauen muss. Der TLB (Translation Lookaside Buffer) ist ein Cache in der MMU, der die zuletzt genutzten Page-Basisadressen bereithält
- MMU sucht Basisadresse zunächst im TLB (Zeitersparnis)
- ist kein passender TLB-Eintrag vorhanden, wird der Eintrag aus der Page-Table geladen und in den TLB übertragen
- für den Zugriff auf die Page-Table wird ein page-table base register (PTBR) und ein page-table length register (PTLR) verwendet
- manche TLBs speichern addresss-space identifiers (einzigartig je Prozess) mit jedem Eintrag, andernfalls muss der TLB bei jedem Kontext-Wechsel geleert werden
- Effective Access Time: Erwartete Zugriffsdauer unter Berücksichtigung der Hit-Rate
Demand Paging
Es werden immer nur diejenigen Seiten geladen, die tatsächlich gebraucht werden
- Programme sind nicht mehr durch physische Speichergröße beschränkt
- Programme brauchen zur Laufzeit weniger Speicher mehr Programme können zugleich im Speicher liegen
- Prozesse können auch effizienter erstellt werden und Seiten teilen
- basierend auf dem Prinzip einer Lokalität
- weniger I/O-Aufwand für Swapping
- Pager: ein Swapper, der nur einzelne Pages swappt
- benötigter Hardware-Support: Page-Table mit valid/invalid-bit, Sekundärspeicher (swap) und Instruktions-Neustart (bei Page Fault)
- Effective Access Time: Erwartete Zugriffsdauer unter Berücksichtigung der Page-Fault-Rate
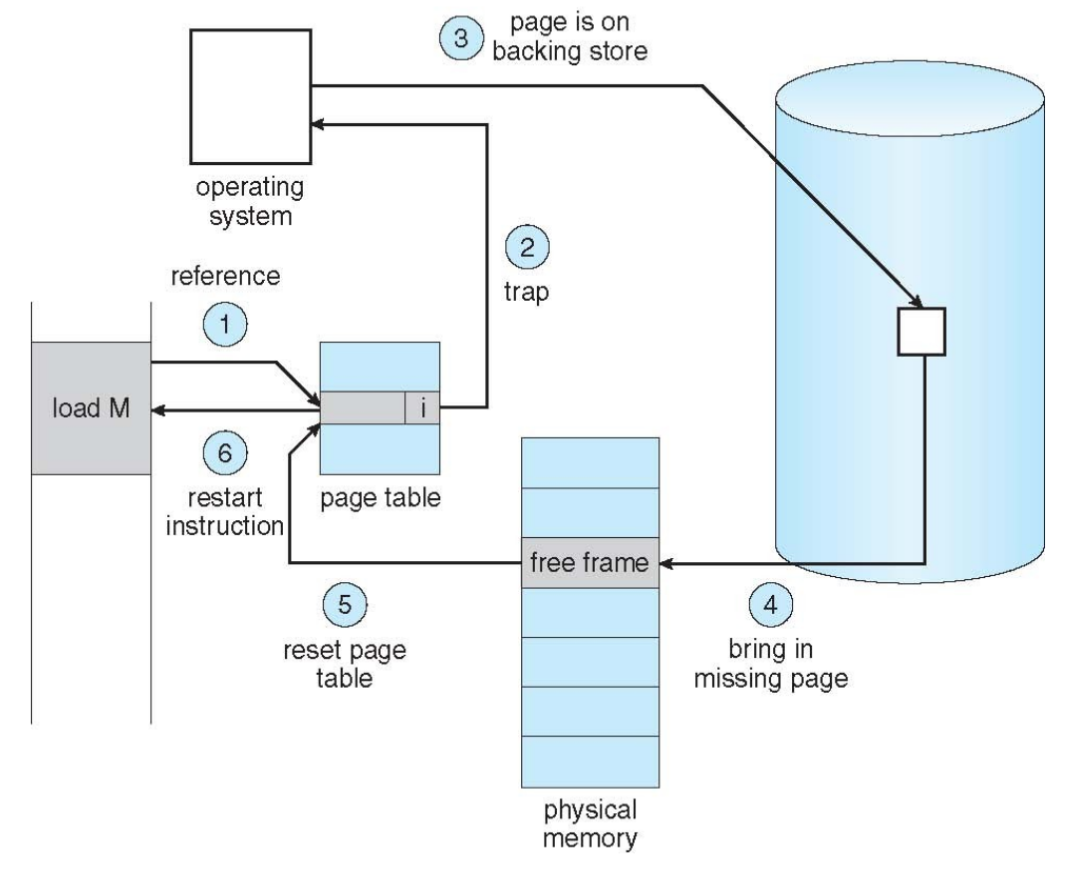
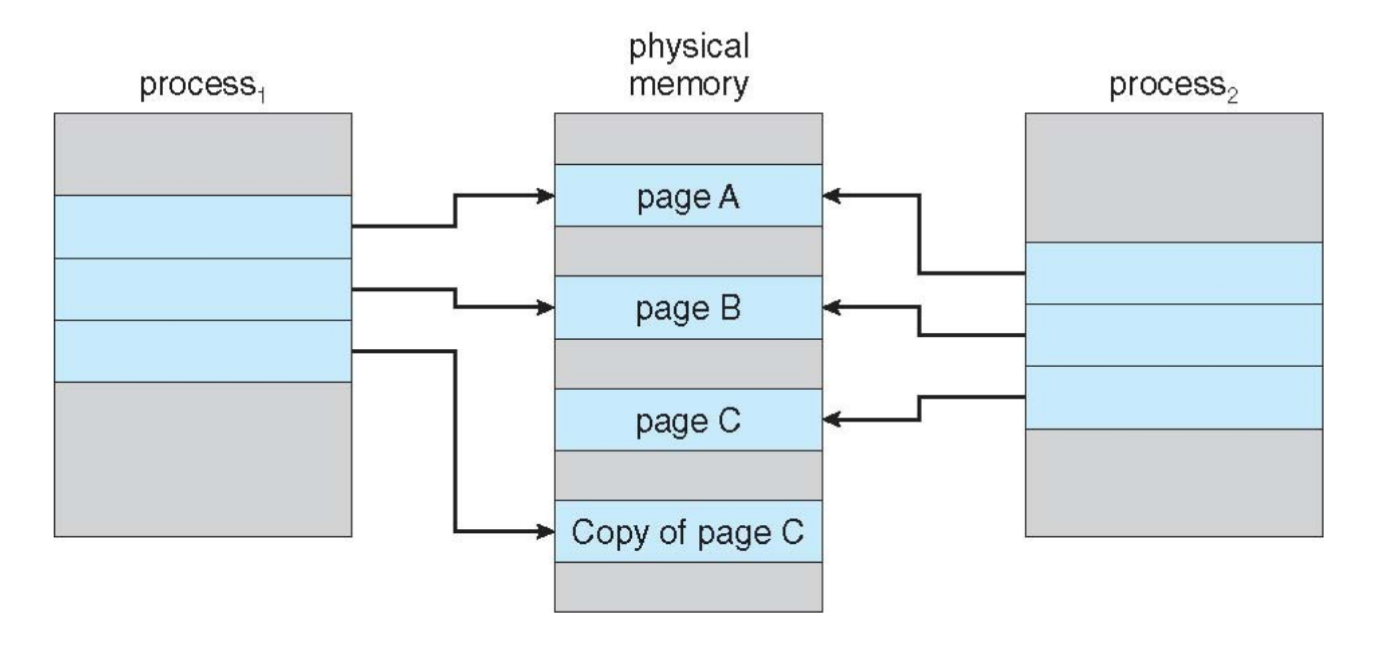
Page Fault (trap to OS)
Ein Seitenzugriffsfehler tritt auf, wenn ein Prozess versucht eine Seite zu laden, die derzeit nicht im Hauptspeicher geladen ist (Valid-Bit nicht gesetzt). Man unterscheidet
- Hard Page Fault: Referenzierte Seite liegt nicht im Hauptspeicher und muss von Disk geladen werden
- Dazu wird zunächst in einer anderen Tabelle geprüft, ob die Seite überhaupt existiert oder der Zugriff vollständig invalid ist
- Soft Page Fault: Referenzierte Seite ist Prozess nicht (mehr) zugeordnet, liegt aber im Hauptspeicher, sodass kein Speicherzugriff nötig wird. Die kann zwei Gründe haben:
- Prozess referenziert shared library, die bereits im Speicher liegt
- Referenzierte Seite liegt noch in der Modified- bzw. Standby-Liste
Working Set
Das Working Set eines Prozesses ist die Menge der Pages, auf die ohne Page Fault zugegriffen werden kann
- es dient als Schätzung der Lokalität, in der ein Prozess sich derzeit bewegt
- oft ermittelt als die Menge der Pages, deren letzte Verwendung durch den Prozess maximal eine gewisse feste Zeitspanne (oft ) zurückliegt
- kann mittels Timer Interrupt und Reference bit approximiert werden
- Page Fault Frequency: direkterer Ansatz, bei dem grundsätzlich local replacement verwendet wird, der Prozess aber zusätzliche Frames erhält, wenn seine Page-Fault-Rate zu hoch ist (bzw. umgekehrt welche verliert bei niedriger Rate)
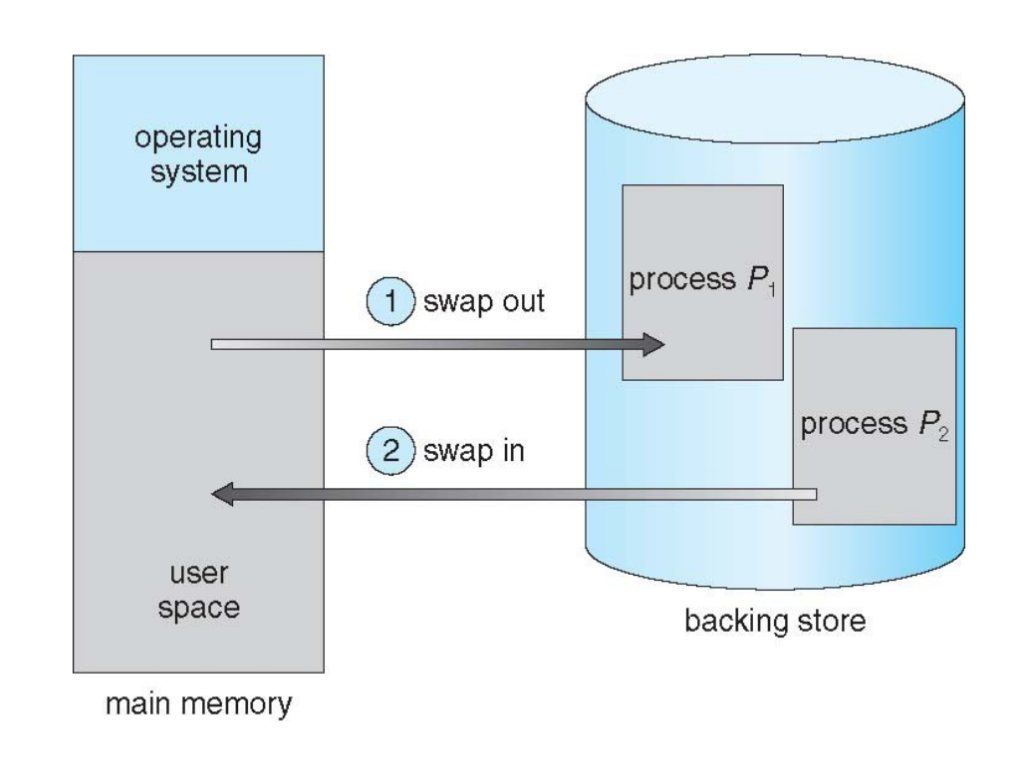
Swapping
Ein Prozess kann temporär aus dem Hauptspeicher heraus in einen backing store geswapped werden
- Backing store: Schnell und groß genug, um Kopien der Prozesse aller Nutzer zu halten
- Roll out, roll in: Variante beim Prioritäten-basierten Scheduling, bei der ein Prozess durch einen anderen mit höherer Priorität ersetzt wird
- Transfer time: proportional zur Größe des zu swappenden Speichers, kann Kontext-Wechsel stark verlangsamen
- UNIX, Linux, Windows: Swapping normalerweise deaktiviert, wird erst ab gewisser Auslastung aktiviert
- Pending I/O: Swapping nicht möglich, da I/O dann im falschen Prozess stattfinden würden
- Double Buffering: I/O wird zunächst in Kernel Space geschrieben und dann vom jeweiligen Prozess behandelt (overhead)
Seitenverwaltung
Windows
Windows verwaltet Pages mittels der folgenden Listen (Page-Buffering Algorithmus):
- Standby Page List: unveränderte Pages, die im Rahmen des Working Set Replacement freigegeben wurden
- Modified Page List: veränderte Pages, die im Rahmen des Working Set Replacement freigegeben wurden
- ab einer gewissen Größe der Liste beginnt der Modified Page Writer Thread diese Pages auf Disk zu schreiben und die Einträge in die Standby Page List zu verschieben
- Free Page List: Liste freier, aber nicht genullter Seiten
- Prozess muss garantieren, den vorhandenen Inhalt sofort zu überschreiben
- zero-fill-on-demand: wenn eine genullte Seite angefordert wird, aber keine in der Zero Page List vorhanden ist, muss eine Seite aus der Free Page List genullt werden
- Zero Page List: Liste genullter Seiten
- Bad Page List: Liste fehlerhafter Seiten
- wird zum Beispiel beim Boot durch Lesen und Schreiben von Bitmustern überprüft
Darüber hinaus erhält jeder Prozess ein Working Set Minimum und ein Working Set Maximum zugewiesen
- wenn der freie Speicherplatz im System zu gering wird, wird Automatic Working Set Trimming auf allen Prozessen ausgeführt, die ihr Minimum überschreiten
Page Frame Number Database
Die Page Frame Number Database enthält für jede physische Seite einen Eintrag von 24 Bit. Aktive/valide Seiten beinhalten
- den originalen PTE Wert
- die virtuelle PTE-Adresse
- einen Working Set Hint
- Flags für die oben genannten Listen
Der Share Count gibt an wie viele Prozesse auf diese Seite zugreifen
- fällt der Share Count auf kann diese Seite in die Free, Standby oder Modified Page List verschoben werden

Swapping vs. Page Replacement
Beim Swapping wird der gesamte Prozess aus dem Hauptspeicher auf Disk geschrieben, um Speicherplatz für andere Prozesse zu schaffen. Im Gegensatz dazu werden beim Page Replacement einzelne Seiten auf Disk geschrieben, um Platz für andere Seiten zu schaffen. Swapping wird in der Regel selten ausgeführt, da durch das Auslagern eines ganzen Prozesses eine hohe Latenzzeit entsteht.
Das Page-Replacement findet häufiger statt, da der Prozess weiterlaufen kann. Solange kein Thrashing auftritt ist das Page Replacement der effizientere Weg.
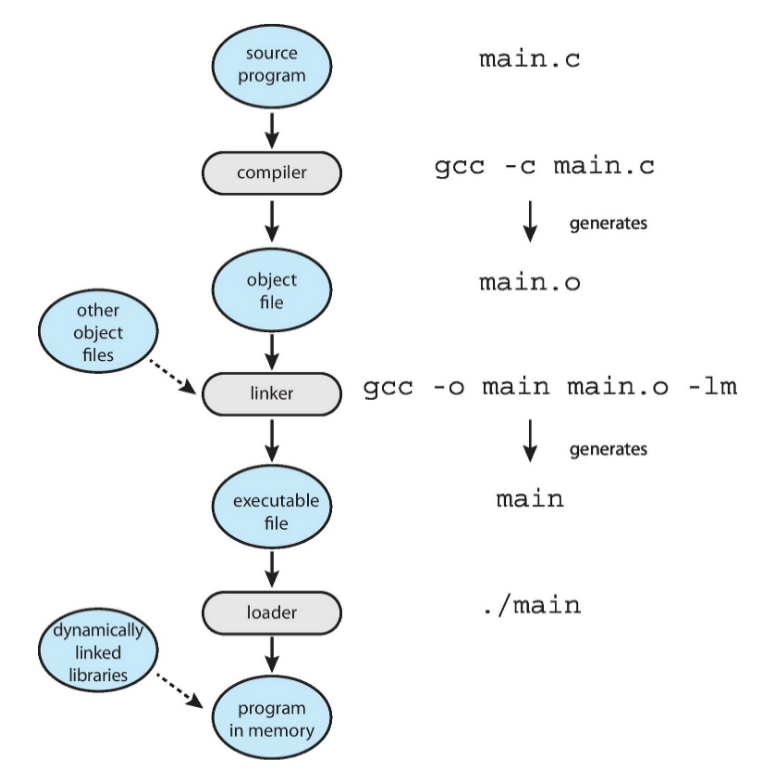
Shared Memory
Mithilfe der bereits erwähnten Page Tables lässt sich Shared Memory ganz einfach so umsetzen, dass einzelne Pages dieser kommunizierenden Prozesse auf dasselbe physische Frame abgebildet werden
- jeweilige Page ist weiterhin ein Bestandteil des zusammenhängenden logischen Adressraumes des Prozesses
- andere Prozesse können aber ebenfalls auf das Frame zugreifen
Copy-on-Write
Die Idee hinter einem Copy-on-Write-Speicher ist die Verzögerung des Kopieren von Pages, etwa bei einem fork-Systemaufruf
- Kind-Prozess verwendet meist nur einige Pages oder ruft eh direkt
execauf - Eltern- und Kind-Prozess verwenden deshalb zunächst dasselbe physische Frame (Shared Memory), dieses wird allerdings als Copy-on-Write markiert
- versucht ein Prozess zu schreiben, so wird zunächst die benötigte Kopie erstellt
- Code-Pages müssen so nie kopiert werden
Page-Replacement Algorithmen
Wenn kein freies Frame mehr verfügbar ist, müssen bestehende Seiten (victim frame) ausgepaged werden
- dabei müssen nur modifizierte Seiten wieder auf Disk geschrieben werden
- Zeitkosten für Page Fault steigen damit weiter
- Frame-allocation algorithm: entscheidet, wie viele und welche Frames jeder Prozess im Speicher zugewiesen bekommt
- Page-replacement algorithm: entscheidet, welches Frame ersetzt werden müssen, um die Page-Fault-Rate zu minimieren
Der First-In-First-Out (FIFO) Algorithmus implementiert eine FIFO-Queue der Seiten eines Prozesses
- Belady’s Anomaly: Die Page-Fault-Rate kann bei mehr verfügbaren Frames steigen
Der Least-Recently-Used (LRU) Algorithmus ersetzt die Seite, die am längsten nicht genutzt wurde
- Implementierung über Timestamp je Page oder alternativ Stack, auf dem Seiten bei Referenzierung nach oben gelegt werden
- leidet genauso wie OPT nicht unter Belady’s Anomaly
- Approximation: reference bit, initial und bei erneutem Zugriff auf gesetzt, wobei nur unbenutzte Seiten mit Bit ersetzt werden
Der Second-Chance Algorithmus speichert sich für jede Seite ein solches reference bit (initial ). Eine Seite, die erneut referenziert wird, bekommt das Bit auf gesetzt. Wenn eine Seite ersetzt werden muss, wird sequentiell nach einer Seite mit Bit gesucht und diese ersetzt, wobei Bit auf gesetzt wird
- wird auch clock-replacement genannt, da ein Zeiger über eine zirkuläre Queue iteriert
- Erweiterung: neben dem reference bit wird auch das modified bit betrachtet und eine Seite aus der niedrigsten nicht-leeren Klasse entfernt (reference wichtiger als modified)
- ggf. muss mehrmals über die Queue iteriert werden
Bei einen Counter Algorithmus werden die Anzahlen dern Seitenzugriffe gezählt
- selten verwendet
- Least Frequently Used (LFU): die am seltensten verwendete Seite wird ersetzt
- Most Frequently Used (MFU): die am häufigsten verwendete Seite wird ersetzt, da seltener verwendete Seiten wohl in Zukunft noch verwendet werden
Frame Allocation
- Minimale Anzahl an Frames je Prozess: Wird bestimmt durch Anzahl der in einer Instruktion adressierbaren Pages (inklusive Zugriffe auf Page-Grenzen)
- Maximale Anzahl an Frames je Prozess: Gesamtzahl der Frames im System
- Fixed Allocation: feste Anzahl, entweder stets gleich oder proportional zur Prozess-Größe
- Priority Allocation: proportionale Verteilung basierend auf Prioritäten, bei einem Page Fault wird ein Frame eines Prozesses mit niedrigerer Priorität ersetzt
- Global replacement: Ersatz-Frame wird aus allen Frames (auch andere Prozesse) ausgewählt
- Local replacement: Ersatz-Frame wird auch den Prozess-eigenen Frames ausgewählt
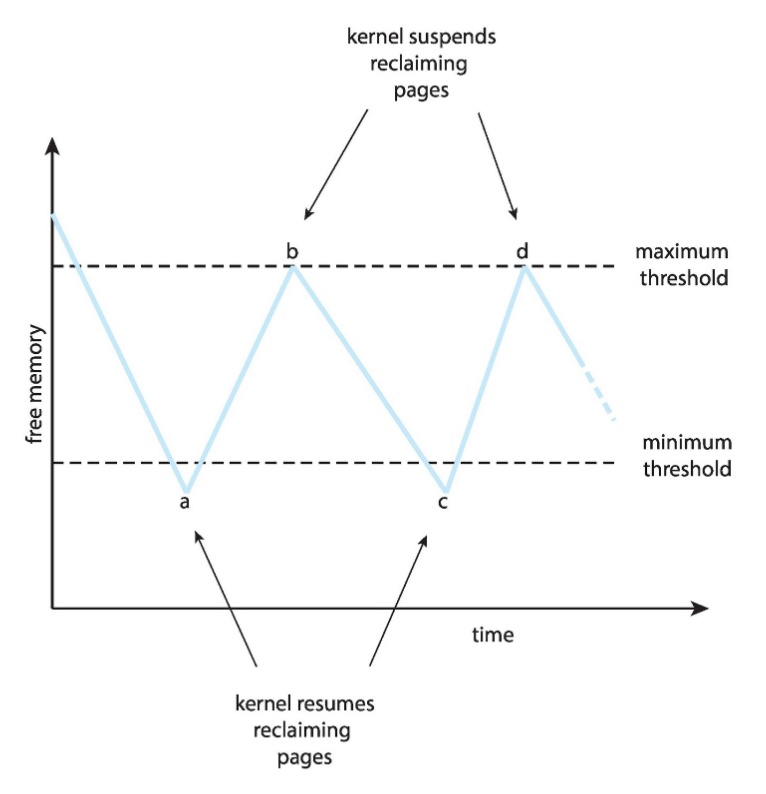
- Reclaiming pages: es wird verhindert, dass die Free Frame List leer wird, indem sich das Betriebssystem ab einer gewissen Grenze Frames in diese zurückholt
- NUMA: Speicher sollte nahe an der CPU zugeteilt werden, auf der der Thread läuft
Thrashing
Wenn ein Prozess zu wenig Seiten im Speicher liegen hat, so ersetzt er diese regelmäßig miteinander (Lokalität verfügbarer Speicher) und hat eine sehr hohe Page-Fault-Rate
- in diesem Fall muss entweder die Anzahl der Frames für den Prozess erhöht oder der Prozess unterbrochen und ausgelagert (Swapping) werden
Kernel Memory
Braucht oft zusammenhängenden Speicher (z.B. für I/O-Geräte)
- Buddy System: Speicher wird zur nächsten Zweierpotenz aufgerundet | wenn der aktuelle chunk zu groß ist, wird er (rekursiv) in zwei gleich Große buddies geteilt
- ungenutzte chunks können wieder zu größerem kombiniert werden
- ggf. viel interne und externe Fragmentation
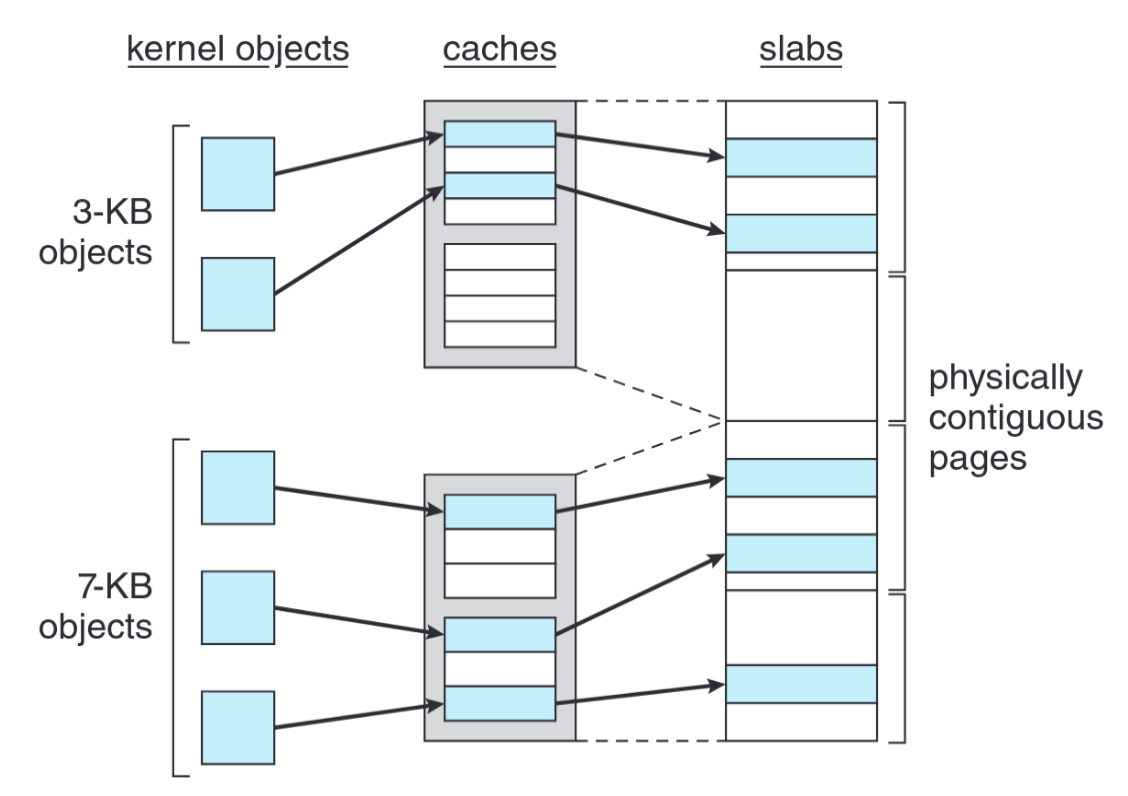
- Slab allocator: Eine slab besteht aus einer oder mehreren zusammenhängenden Frames, ein cache aus einer oder mehreren slabs
- für jede Kernel-Datenstruktur wird ein cache angelegt und mit free objects gefüllt
- sind alle Objekte used, so wird auf die nächste slab zugegriffen bzw. eine neue angelegt (slab-Zustände: full, partial, empty)
- Linux:
struct task_sctruct(~ 1.7 KB)
Weitere Überlegungen
- Prepaging: Seiten vorladen, um initiale Page Faults zu verhindern
- Page size: meist 4KB bis 4MB | beeinflusst Fragmentation, Page-Table- und TLB-Größe, I/O-overheads, Lokalitäten, etc.
- TLB Reach: TLB-Größe Page-Größe | sollte mindestens das Working Set jedes Prozesses halten können
- I/O Interlock: Seiten müssen manchmal fest im Speicher gehalten werden (z.B. Kopieren von I/O-Gerät)
- Clustering: auch Seiten neben einer durch Page Fault betroffenen Seite werden geladen (z.B. verwendet von Windows)
Beispiele
Beispiele Einfügen (Blatt 5 Aufgabe 12) - Fehler bei FiFo