Phasen des Datenbankentwurfs
- Anforderungsanalyse: Sammlung des Informationsbedarfs in den Fachabteilungen
- Konzeptioneller Entwurf: Erste formale Beschreibung des Fachproblems ER-Modell
- Auflösung von Namenskonflikten, Typkonflikten, Wertebereichskonflikten, Bedingungskonflikten und Strukturkonflikten
- Verteilungsentwurf: Art und Weise der verteilten Speicherung (optional) festlegen
- vertikale vs. horizontale Partitionierung
- Logischer Entwurf: Datenmodell des ausgewählten DBMS in logischem (nicht physischem) Schema darstellen
- ER Relationales Modell
- Normalisierung (Redundanzvermeidung)
- Datendefinition: Umsetzung des logischen Schemas in ein relationales Schema
- Physischer Entwurf: DBMS nimmt automatisiert physischen Entwurf vor (echte Daten auf der Festplatte)
- ggf. Einrichtung von Indizes
- Implementierung und Wartung: Anpassungen, Wartung, Tuning, Portierung (neues Datenbankmanagementsystem) etc.
- kosten- und zeitaufwendigste Phase
Wichtigkeit des Entwurfs: Verwendung für viele Jahre, Redundanz und unnötige Daten vermeiden, etc.
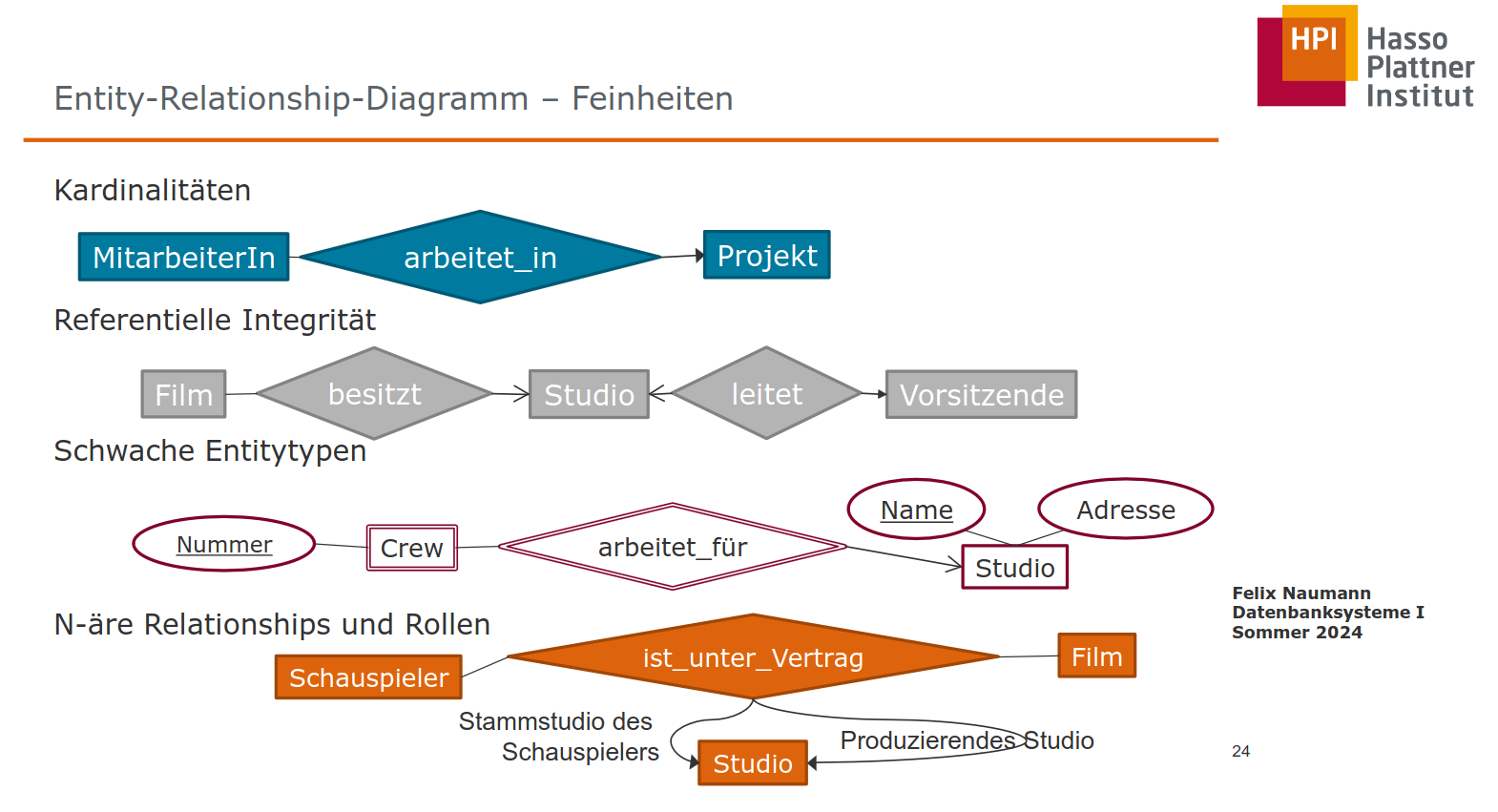
ER-Diagramme
- Entitytypen + Entities (Objekt der realen Welt oder Vorstellungswelt)
- Relationshiptypen + Relationships (zwischen obigen Entitäten, meist binär)
- Attribute (sowohl an )
- wir betrachten IST-Beziehung nur als Bäume
- Entities aus der Subklasse sind auch in der Superklasse repräsentiert
- Entities sind in allen Subklassen repräsentiert, in die sie gehören
Nebenbedingungen: sind Teil des Schemas, nicht der Daten. Dazu gehören:
- Schlüssel
- referenzielle Integrität (Existenz referenzierter Objekte)
- Domänen (eingeschränkte Wertebereiche)
- Assertions und ähnliches
Schlüssel
Minimale Menge an Attributen eines Entitytyps, sodass keine zwei Entities in allen Schlüsselattributen übereinstimmen (natürlich vs. nicht natürlich / generiert wie z.B. ID)
- für jeden Entitytp muss ein Schlüssel angegeben werden
- es kann mehrere Schlüssel für einen Entitytyp geben, dann wird üblicherweise ein Primärschlüssel ausgewählt (in ER-Diagramm nur ein Schlüssel darstellbar)
- bei IST-Beziehungen müssen sämtliche Schlüsselattribute in der Wurzel-Superklasse enthalten sein
Fehlende Schlüssel wirken kapazitätserhöhend (unerlaubte Tupel sind dadurch möglich)
Zusätzliche Schlüssel wirken kapazitätsvermindernd (erlaubte Tupel werden dadurch unmöglich)
Referenzielle Integrität
offener Pfeil: → (genau ein)
sonst geschlossener Pfeil: —▸ (höchstens ein)
Beispiel: n:1 Relationship zwischen “Film” und “Studio”
- Ein Film gehört zu genau einem Studio (mit RI)
- Ein Film gehört zu höchstens einem Studio (ohne RI)
Erzwingung der RI: DBMS-spezifisch (z.B. Studio mit Filmen darf nicht gelöscht werden / Filme werden mit Studio gelöscht)
Relationen
- Eine Relation ist eine Menge an -Tupeln
- Dinge, die in der Relation stehen, bilden ein -Tupel, das Element von ist
- Teilmenge des kartesischen Produkts
- Mengen sind Domänen (Wertebereiche wie z.B. Integer, String, Boolean, etc.)
- Tupel sind Datenwerte
Relationales Modell erstellen
Grundidee: Jeder Entitytyp und jeder Relationshiptyp wird mit seinen Attributen eine Relation übersetzt.
- Relationshiptypen übernehmen zusätzlich Schlüsselattribute der beteiligten Entitytypen und müssen bei doppelten Bezeichnungen umbenannt werden
- Zusammenlegen von Relationen bei 1:n-Beziehung möglich (inklusive Sonderfall 1:1)
Achtung: Gleiches Schema bei Relationen bedeutet nicht gleiche Domäne / Bedeutung
Schwache Entitytypen
- Relation des schwachen Entitytypen muss Schlüssel aller relevanten Entitytypen enthalten
- schwacher Relationshiptyp ist redundant, normaler Relationshiptyp übernimmt auch alle relevanten Schlüssel (Zweck: Identifizierung)
Achtung: Wenn ein Relationshiptyp einen Entitytyp vollständig umfasst, kann letzterer dennoch benötigt werden, falls gar keine Relationships für die Entity auftreten (Entity kann ohne Relationship sonst nicht dargestellt werden)
IST-Beziehung (Spezialisierung)
Keine eigene Relation für IST-Beziehung! Stattdessen:
- ER-Stil: Eigene Relationen für Entitytpen jeder Hierarchiebene
- Relationen
- ggf. große Redundanz ⇒ großer Speicherbedarf
- Anfragen an Wurzelentitätstyp schnell, spezifische Anfragen nur mithilfe von Joins über die Relationships
- Objekt-orientierter Stil: Eigene Relation für jede mögliche Kombination aus vorliegenden Spezialisierungen (Abhilfe etwa mithilfe von Views)
- Relationen
- geringster Speicherbedarf, da keine Redundanz
- Anfragen an Wurzelentitätstyp nur über (nicht so teure) Unions möglich, spezifischere Anfragen schneller
- Nullwert-Stil: Eine einzige Relation mit allen möglichen Attributen, möglicherweise mit
NULL-Wert belegt (ggf. Informationsverlust durch “natürliche”NULL-Werte, Lösung: zusätzliche Attribute)- Relation
- ggf. zahlreiche Nullwerte ⇒ großer Speicherbedarf
- keine (teuren) Joins notwendig, alle Anfragetypen leicht zu bearbeiten

Normalisierung
Funktionale Abhängigkeiten (FDs)
: bestimmt funktional, also Übereinstimmung in der Attributmenge Übereinstimmung in der Attributmenge
- Schreibweise: auch statt erlaubt
- Funktionale Abhängigkeiten sind Eigenschaften des Schemas, nicht der Instanz (spezifische Daten)
- Dekomposition (rechte Seite auseinanderziehen) und Vereinigung (rechte Seite verbinden) erlaubt
- FDs sind transitiv (FD-Ableitung)
Herkunft von FDs
- aus der Deklaration eines Schlüssels
- aus der Deklaration von FDs, z.B. durch Expertenwissen
- aus den Naturwissenschaften, z.B. Einhaltung physikalischer Gesetze
- aus einem ER-Diagramm über markierte Schlüsselattribute
- Data Profiling: alle FDs entdecken und die “besten” als echt deklarieren
Triviale FDs
- trivial: Attribute rechts sind Teilmenge der Attribute links
- nicht-trivial: rechts ein Attribut, das links nicht vorkommt
- völlig nicht-trivial: beide Attributmengen disjunkt
Schlüssel (neu definiert)
Eine Attributmenge ist ein Schlüssel einer Relation , wenn sie alle (anderen) Attribute von funktional bestimmt und keine echte Teilmenge der Attributmenge ebenfalls diese Eigenschaft hat
- ein Schlüssel ist also stets minimal (in Bezug auf Teilmengen)
- kleinster Schlüssel: der Schlüssel mit den wenigsten Attributen
- Superschlüssel: Attributmenge, die einen Schlüssel enthält
- bei mehreren Schlüssel wird meist ein Primärschlüssel ausgewählt
FD-Mengen
Zwei Mengen und an FDs heißen äquivalent, wenn die Menge der gültigen Instanzen unter und jeweils gleich sind.
Eine Menge an FDs folgt aus einer Menge an FDs, falls jede unter gültige Instanz auch unter gültig ist.
Hüllenbildung
Gegeben eine Menge an Attributen und eine Menge an FDs .
- Die Hülle von unter ist die Menge aller Attribute für die gilt, dass für jede unter gültige Relation auch gilt
- also Menge der funktional ableitbaren Attribute
- Notation: Hülle von ist
- Berechnung: Wiederholt nach anwendbaren FDs suchen
Basis
Eine Menge an FDs, aus der alle anderen FDs abgeleitet werden können
- Wenn keine echte Teilmenge der Basis wiederum eine Basis ist, dann ist die Basis minimal
Armstrong-Axiome
- Axiomatisieren FDs und ihre Ableitung
- korrekt, vollständig und minimal (d.h. kein Axiome aus den anderen herleitbar)
- Reflexivität: (triviale FDs)
- Akkumulation:
- Transitivität:
FDs nach Projektionen
- Gegeben eine Relation mit Menge an FDs. Sei das Ergebnis nach Entfernung einiger Attribute aus (“Projektion”)
- Für gelten alle FDs, die aus folgen und nur Attribute aus verwenden
- Algorithmus: Hülle jeder Teilmenge von mit den FDs aus bilden und daraus resultiernde FDs überprüfen. Tricks:
- Hülle der leeren Menge und Menge aller Attribute muss nicht gebildet werden
- Falls die Hülle von alle Attribute enthält, gilt das auch für alle Supermengen von (müssen also nicht mehr betrachtet werden)
Redundanzvermeidung
Anomalien durch Redundanz und schlechtes Design
- Redundanz kann zu Update-Anomalien führen (nicht alle redundanten Informationen werden geändert)
- Redundanz kann zu Insert-Anomalien führen (neue Informationen widersprechen bereits gespeicherten)
- Bei Delete-Anomalien werden mehr Informationen gelöscht als gewollt (zu viele Informationen in einem Tupel enthalten, stattdessen aufteilen)
Dekomposition
Aufteilung einer Relation in zwei Relationen und
- es muss gelten
- Überlappung erlaubt, z.B. für Schlüssel sinnvoll
- die neuen Relationen dürfen nur durch Projektionen entstehen (also Attributwerte werden ausschließlich übernommen)
Boyce-Codd-Normalform
- Eine Relation ist in BCNF genau dann, wenn für jede nicht-triviale FD ist die linke Seite der FD ein beliebiger Superschlüssel (inklusive minimale Schlüssel) ist
Dekomposition für BCNF
- beruhend auf FDs, die keinen Schlüssel als Teilmenge in der linken Seite haben (verletzende FDs)
- dabei rechte Seite der FD möglichst groß wählen (expandieren durch Hüllenbildung)
- Beispiel:
- neue Relation:
- + alle anderen Attribute (weder noch )
- wiederherstellbar durch Join (über die gemeinsamen Attribute auf der linken Seite der FD)