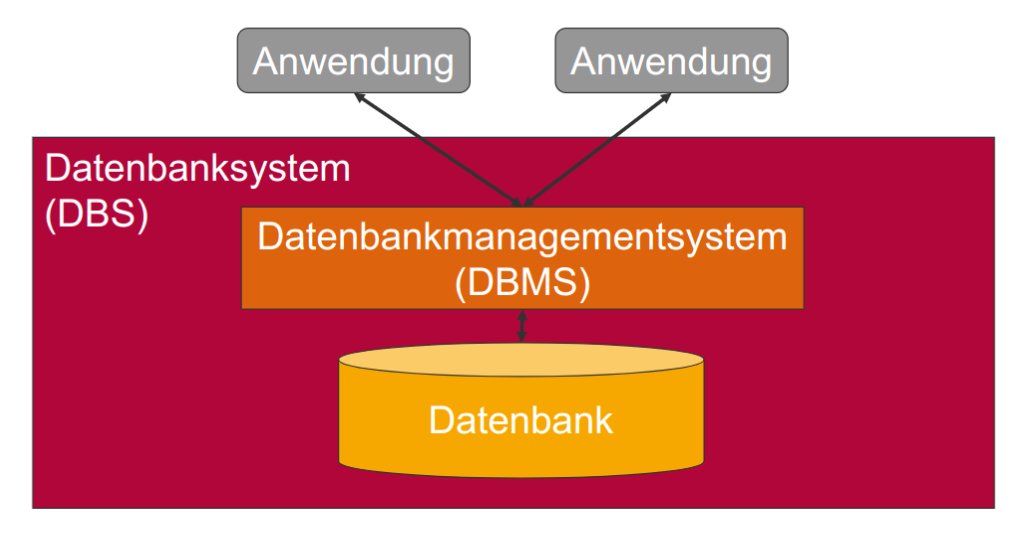
Grundbausteine einer Datenbank
- Anwendung
- Datenbanksystem (DBS) bestehend aus
- Datenbankmanagementsystem (DBMS, Verbindung zwischen Anwendung und Datenbank)
- Datenbank (physischer Speicher)
Anforderungen an DBMS
- Integration: einheitliche, nichtredundante Datenverwaltung
- Operationen: definieren, speichern, abfragen, ändern | alles deklarativ
- Benutzersichten: für verschiedene Anwendungen und individuelle Umstrukturierung
- Integritätssicherung: Korrektheit und Konsistenz des Datenbankinhalts
- Transaktionen: mehrere DB-Operationen als Funktionseinheit | z.B. Änderung mehrere Kontostände bei Überweisung
- Synchronisation paralleler Transaktionen
- Datenschutz: nicht-autorisierte Zugriffe vermeiden | Accounts und Rechte
- Datensicherung: Wiederherstellung nach Systemfehlern, Persistenz
- Katalog: Datenbankbeschreibung / Data Dictionary
Keine Anforderung nach Codd (nicht funktional):
- Anfrageoptimierung: effiziente Ausführung, unterstützt durch Deklarativität
- Datenbackups: Sicherungskopien von Festplatte anlegen und verwalten
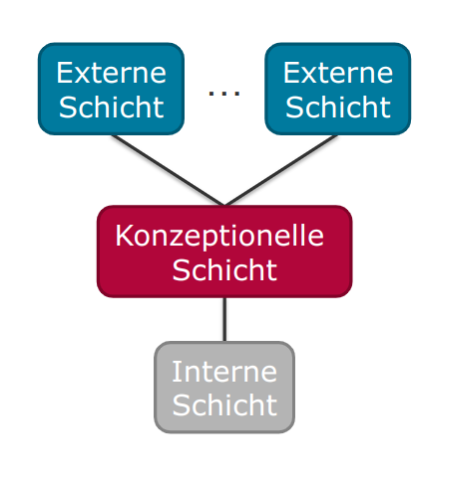
Schichtenmodell für Schemata
Häufig in 3 Schichten unterteilt (vorgeschlagen durch ANSI-SPARC-Architektur von 1975):
- Interne Schicht / Sicht
- Speichermedium (Tape, Festplatte)
- Speicherort (Block, Segmente, Zylinder)
- Dateien, Seiten, Blocks
- Konzeptionelle (logische) Schicht / Sicht
- Unabhängig von physischer Schicht
- Definiert durch Datenmodell
- Stabiler Bezugspunkt für andere beiden äußeren Schichten
- Relationen, Attribute, Tupel, Integritätsbedingungen, Typen
- Externe (logische) Schicht / Sicht
- Anwendungsprogramme
- Nur auf die relevanten Daten
- Enthält möglicherweise Aggregationen und Transformationen
- SQL Views (Sichten), Anwendungen
Begriffe: Tupel auf der Festplatte gespeichert = Record / Datensatz
Datenunabhängigkeit
Die drei Schichten sind in dem Sinne entkoppelt, dass sie unabhängig voneinander gewartet, ausgebaut und verbessert werden.
Ziele:
- Portierbarkeit (DBS lässt sich austauschen, solange SQL-Standard eingehalten wird)
- Tuning vereinfachen
- Standardisierte Schnittstellen
- Stabilität der Benutzer- und Anwendungsschnittstelle gegen Änderungen
Physische Datenunabhängigkeit (Implementierungsunabhängigkeit):
- Änderung an Dateiorganisation / Zugriffspfade haben keinen Einfluss auf konzeptuelles Schema
Logische Datenunabhängigkeit (Anwendungsunabhängigkeit):
- Änderungen an konzeptuellen (und gewissen externen) Schemata haben keine Auswirkungen auf andere externe Schemata und Anwendungsprogramme
Historie der Datenbanksysteme
Vor SQL: Lochkarten Festplatten (teuer, groß, wenig Speicher) Festplatten (günstig, klein, viel Speicher) 60er: hierarchische DBS (Dateien, schwache Ebenentrennung, navigierende DML) 70er und 80er: relationale DBS (Tabellen, 3 Ebenen, deklarative DML)
Nach SQL: 80er und 90er: Objektorientierte DBS 2000er: Spezialisierung auf neue Daten-Arten 2010er: Web-scale, NoSQL, Cloud 2020er: AI / Data Science
JDBC
Motivation
Grenzen von SQL:
- Bedingte Anweisungen (
update ifund ähnliches) - Darstellung von Daten (z.B. für Web-Anwendungen)
- Komplizierte Fragestellungen (z.B. ähnliche Tupel erkennen)
- String-Operationen (z.B. String-Splitting auf Adressen u.ä.)
Impedance Mismatch: Verwendung unterschiedlicher Datenmodelle
- Relationales Modell (DBMS)
- Primitive: Relationen und Attribute
- Kontrolle: Nebenbedingungen
- Modell: Deklarativ
- Generisches Modell (Programmiersprachen)
- Primitive: Pointer, verschachtelte Strukturen und Objekte
- Kontrolle: Schleifen und Verzweigungen
- Modell: Imperativ (meistens)
- Datentransfer notwendig, aber nicht trivial
Anwendungsfälle:
- Erweiterung der DBMS-Funktionalität: Stored procedures
- z.B. neue Aggregationsfunktionen, Operationen auf Strings
- Zugriff auf DBMS innerhalb von Programmiersprachen
- z.B. Laden und Speichern von Daten und Objekten
DBMS-Zugriff aus Programmiersprachen
- Embedded SQL: Integriert SQL in andere Programmiersprache
- z.B. ADA, C, C++, Cobol. Fortran, etc.
- veraltet
- DBMS-Funktionsbibliotheken
- Call-Level-Interface (CLI) für C
- Java Database Connectivity (JDBC) für Java
- Object-Relational-Mappings
- Speichert Repräsentation der Objekte in Datenbank
- Explizites Mapping der Objektfelder auf Attribute
JDBC
- Teil des
java.sqlPackage
Verbindungsaufbau:
String URL = "jdbc:postgresql://<server>:<port>/<db_name>";
String name = "<username>";
String pw = "<password>";
Connection con = DriverManager.getConnection(URL, name, pw);Statements:
Statement stmt = conn.createStatement(); // statement
PreparedStatement pstmt = conn.prepareStatement(<Anfrage>); // prepared statement
ResultSet rs = stmt.executeQuery(<Anfrage>);
ResultSet rs = pstmt.executeQuery();
stmt.executeUpdate(UpdateAnfrage)
pstmt.executeUpdate()Result set:
next()liefert nächstes Tupel bzw.falsegetString(i)/getInt(i)/getFloat(i)liefert Wert des i-ten Attributs
Parametrisierte Anfragen:
String studioName = "Pixar Animation Studios";
String studioAdr = "Emeryville, Vereinigte Staaten";
PreparedStatement studioStmt = conn.prepareStatement(
"INSERT INTO Studio(Name, Adresse) VALUES(?, ?)");
studioStmt.setString(1, studioName); // wird escaped
studioStmt.setString(2, studioAdr);
studioStmt.executeUpdate();Nachteile:
- generische Klassen (
ResultSet,Rowetc.) - nicht objekt-orientiert, keine statischen Typ-Checks
Object-Relational-Mapping
Idee: 1 Objekt = 1 Tupel, 1 Klasse = 1 Tabelle
- Mapping von Basis-Datentypen
- z.B. durch XML oder Annotationen
- Pointer als Fremdschlüssel
Vorteile:
- einfache Kombination beider Datenmodelle / Paradigmen
- Persistieren der Objekte eines Programms einfach
Nachteile:
- Programmieren komplizierter (Operationen ggf. ineffizient)
- Manche Datenstrukturen (z.B. Linked List) eignen sich schlecht für ORMs Impedance Mismatch nur teilweise gelöst
- Enge Kopplung der Datenbanktabelle an das Programms
- Versteckt viel Komplexität, was nicht immer gut ist