- meist verbreitete Datenbankanfragesprache
- ad-hoc und einfach
- deklarativ (nicht imperativ ⇒ optimierbar)
- very-high-level Language
- Anfragen an relationale Algebra angelehnt
- zusätzlich DDL (Data definition language)
- zusätzlich DML (Data manipulation language)
Anfragen
SELECT ... FROM ... WHERE
- Groß- und Kleinschreibung wird nicht beachtet (Keywords + Attribute)
- Konvention: Keywords groß, Schemaelemente klein
- Ausführungsreihenfolge:
FROMdannWHEREdannSELECT
Projektion:
- Alle Attribute:
SELCET * FROM Film - Projektion auf drei Attribute:
SELECT Titel, Jahr, inFarbe FROM Film
Erweiterte Projektion:
- Umbenennung:
SELECT Titel AS Name, Jahr AS Zeit FROM Film - Arithmetischer Ausdruck:
SELECT Titel, Länge * 0.016667 AS Stunden FROM Film - Konstanten:
SELECT Titel, Länge * 0.016667 AS Stunden, 'std.' AS inStunden FROM Film
Selektion:
- Spezifikation in
WHEREKlausel - Bedingungen wie in einer Programmiersprache
- Vergleichsoperationen:
=, <>, <, >, <=, >= - Operanden: Konstanten und Attributnamen (auch wenn nicht in
SELECTgenannt) - Arithmetische Ausdrücke für numerische Attribute, z.B.
(Jahr - 1930) * (Jahr - 1930) <= 100 - Konkatenation für Strings
Vorname || ' ' || Nachname - Logische Verknüpfung durch
AND,OR,NOT - Duplikateliminierung:
SELECT DISTINCT
Sortierung:
ORDER BY-Klausel ans Ende der AnfrageASCals default, alternativDESC
Anfragen über mehrere Relationen
Kreuzprodukt und Join:
SELECT Name
FROM Film, Manager
WHERE Titel = `Star Wars`
AND ProduzentID = ManagerID;- Kreuzprodukt, Selektionsbedingung, Joinbedingung
- alternativ auch:
SELECT Name
FROM Film JOIN Manager ON ProduzentID = ManagerID
WHERE Titel = `Star Wars`;Join-Familie:
- Explizitere Angaben zur Art des Join möglich
- Kreuzprodukt:
Film CROSS JOIN spielt_in - Theta Join durch Angabe von
WHERE-Klauseln - Natural Join, eliminiert redundante Attribute:
Schauspieler NATURAL JOIN Manager - Outer Joins:
NATRUAL INNER JOIN,NATURAL LEFT OUTER JOIN,NATURAL RIGHT OUTER JOIN,FULL OUTER JOIN
Uneindeutige Attributnamen:
- Bei gleichen Attributnamen aus mehreren beteiligten Relationen Relationenname als Präfix:
SELECT Schauspieler.Name, Manager.Name
FROM Schauspieler, Manager
WHERE Schauspieler.Adresse = Manager.Adresse- Präfix auch erlaubt, wenn Attributname eindeutig ist
- Alternativ auch Nutzung von Aliasen / Tupelvariablen möglich
SELECT S.Name, M.Name
FROM Schauspieler S, Manager M
WHERE S.Adresse = M.Adresse- äquivalent zu
Schauspieler AS S
Mengenoperationen:
- in Edge-Cases (z.B. durch leere Relation beim Kreuzprodukt) können SQL-Anfragen von relationaler Algebra abweichen
- deshalb auch Mengenoperationen möglich:
SELECT *
FROM
(
(SELECT A FROM R)
INTERSECT
(SELECT * FROM
(SELECT A FROM S)
UNION
(SELECT A FROM T)
)
)- zumindest laut Standard immer in Verbindung mit
SELECT-Klausel sowie geklammerten Anfrageergebnissen - durch Verwendung von Mengenoperationen implizit in Mengensemantik (für Input und Output)
- Mengensemaktik:
INTERSECT,UNION,EXCEPT/MINUS - Multimengensemantik:
INTERSECT ALL,UNION ALL,EXCEPT ALL/MINUS ALL
Geschachtelte Anfragen
Skalare Subanfragen
- allgemeine Anfragen produzieren Relationen
- spezielle Anfragen garantieren, dass nur ein Tupel mit einem Attribut Ergebnis der Anfrage ist
- dann erlaubt DBS die Verwendung als Wert / Konstante
- “Skalare Anfrage”
- falls keine Zeile:
NULL - falls mehr als ein Tupel: Laufzeitfehler (kein Syntaxfehler)
SELECT Name
FROM Manager
WHERE ManagerID =
( SELECT ProduzentID
FROM Film
WHERE Titel = ‘Star Wars‘ AND Jahr = ‘1977‘ );SELECT a.Name, a.Standort
FROM Abteilung a
WHERE
(SELECT AVG(bonus)
FROM personal p
WHERE a.AbtID = p.AbtID)
>
(SELECT AVG(gehalt)
FROM personal p
WHERE a.AbtID = p.AbtID)Bedingungen mit Relationen
EXISTS R: gibtTRUEzurück, fallsRnicht leerx IN R: gibtTRUEzurück, fallsxgleich einem Wert inRx NOT IN Rbzw.x <> ALL R: gibtTRUEzurück, fallsxkeinem Wert inRgleichtx > ALL R: gibtTRUEzurück, fallsxgrößer als jeder Wert inR- entsprechend für die anderen Vergleichsoperatoren
x > ANY Rbzw.x > SOME R: gibtTRUEzurück, fallsxgrößer als irgendein Wert inR- entsprechend für die anderen Vergleichsoperatoren
- Negation mit
NOT(...)immer möglich
x kann auch Tupel anstelle von Wert sein
- dann gleiches Schema und gleiche Attributreihenfolge vorausgesetzt
Subanfragen
-
meist in
WHERE-Klausel -
allerdings auch in
FROM-Klausel möglich Alias muss vergeben werden- Definition der U nteranfrage lässt sich dann mit
WITH (...) ASauslagern
- Definition der U nteranfrage lässt sich dann mit
-
unkorreliert: Subanfrage muss einmalig ausgeführt werden und kann dann wiederholt verwendet werden
-
korreliert: Müssen mehrfach ausgeführt werden, einmal pro Bindung der korrelierten Variable der äußeren Anfrage | Abhängigkeit
Operationen auf einer Relation
Duplikateliminierung:
- Relationale DBMS verwenden i.d.R. Multimengensemantik
- Duplikate entstehen durch:
- Einfügen / Verändern von Tupeln und Basisrelationen
- Projektionen
- Subanfragen (z.B.
UNION ALL)- oft verhindern Subanfragen (z.B.
IN) auch bereits ungewollte Duplikate
- oft verhindern Subanfragen (z.B.
- Vermehrung von Duplikaten durch Kreuzprodukt
SELECT DISTINCT, allerdings mit hohen Kosten verbunden (z.B. Sortierung / Hashing)
Aggregation:
SUM, AVG, MIN, MAX, COUNT- oft auch enthalten
VAR, STDDEV COUNT(*)zählt Anzahl der Tupel- in allen anderen Fällen wird
NULLignoriert - auch als
SUM(DISTINCT Gehalt)möglich
- in allen anderen Fällen wird
Gruppierung:
GROUP BYim Anschluss an dieWHERE-Klausel- Nicht-aggregierte Werte der
SELECT-Klausel müssen in derGROUP BY-Klausel erscheinen NULList eigener Gruppierungswert
“Sorten” der Attribute in SELECT-Klausel (jeweils optional):
- Gruppierungsattribute
- Aggregierte Attribute
Ausführungsreihenfolge:
FROM-KlauselWHERE-KlauselGROUP BY-KlauselSELECT-Klausel
HAVINGals zusätzliche Auswahl auf der jeweils aktuellen Gruppe (ähnlich zuWHERE, allerdings nur Gruppierungsattribute und beliebige aggregierte Attribute erlaubt)
Besondere Datentype und Werte
Strings
- Intern verschiedene Datentypen, aber miteinander vergleichbar
- Vergleiche mit
=, <, >, <=, >=, <>- Lexikographisch
- Sortierungsreihenfolge in Spezialfällen von DBMS abhängig
- Zusätzlich Vergleiche mit
LIKEbzw.NOT LIKE%= für beliebige Sequenz von 0 oder mehr Zeichen_= ein beliebiges Zeichen
Datum und Uhrzeit
- Datumskonstante:
DATE 'YYYY-MM-DD' - Zeitkonstante:
TIME 'HH:MM:SS.S' - Zeitstempel
TIMESTAMP 'YYYY-MM-DD HH:MM:SS.S' - Entsprechende Vergleiche und Selektionen
Nullwerte
NULLbzw ⊥- Mögliche Interpretationen: Unbekannter Wert, Wert unzulässig, Wert unterdrückt
- Vergleiche in
WHEREüberIS NULLbzw.IS NOT NULL - Regeln für Umgang in arithmetischen Interpretationen und Vergleichen:
- Arithmetische Operationen mit
NULLergebenNULL - Vergleich mit
NULLergibt WahrheitswertUNKNOWN NULList keine Konstante, sondern nur Attributwert (deswegen Vergleiche mitIS)
- Arithmetische Operationen mit
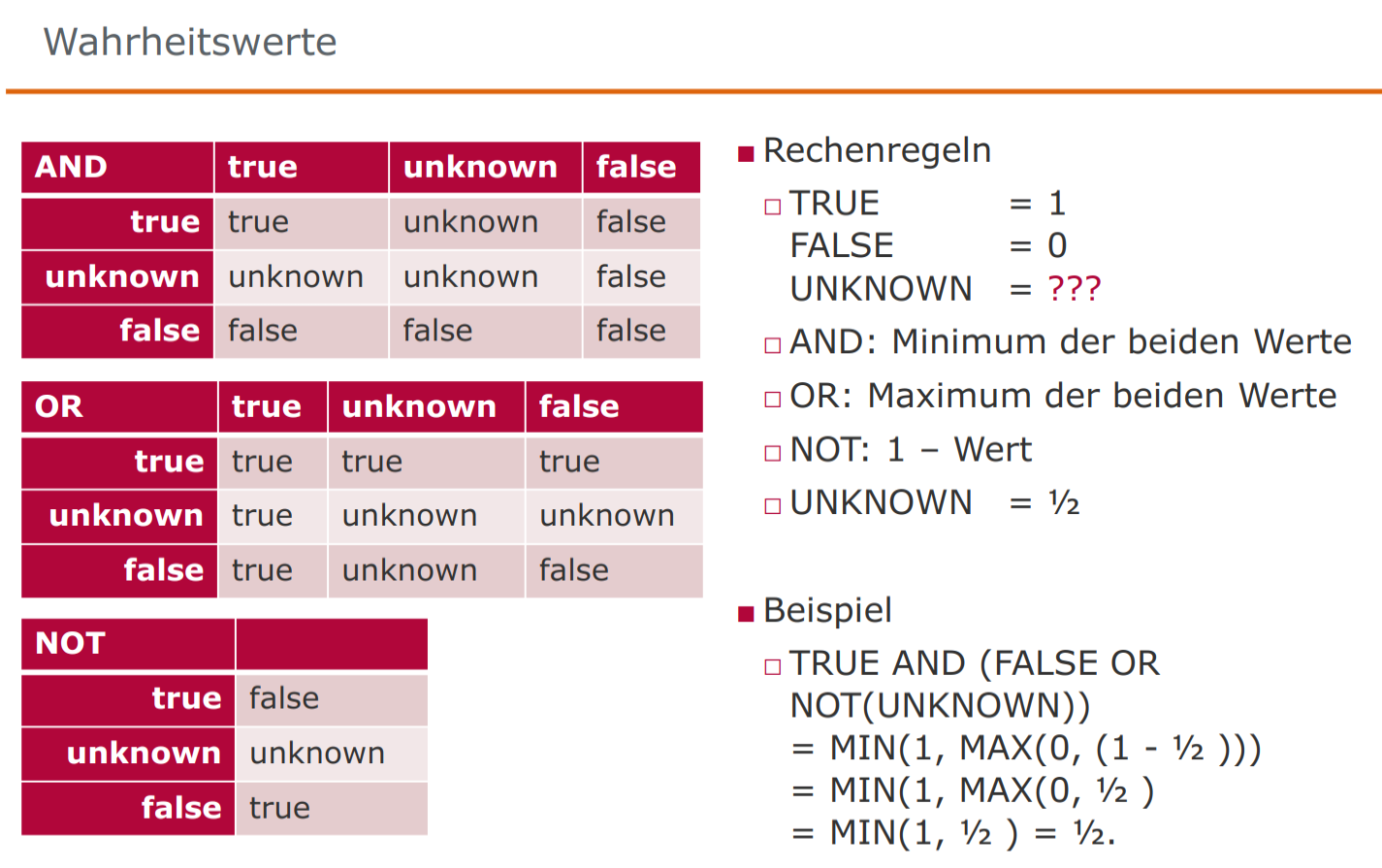
Wahrheitswerte
TRUE,FALSEundUNKNOWNWHERE UNKNOWNerscheint nicht im Ergebnis
- Ausführungspriorität:
NOTdannANDdannOR
Datenbearbeitung (DML)
- Data manipulation language
- CRUD:
- Create (
INSERT INTO ... VALUES ...) - Read (
SELECTwie bekannt) - Update (
UPDATE ... SET ... WHERE ...) - Delete (
DELETE FROM ... WHERE ...)
- Create (
Insert
INSERT INTO spielt_in(FilmTitel, FilmJahr, Schauspieler)
VALUES (‘Star Wars‘, 1977, ‘Alec Guinness‘);Wenn alle Attribute gesetzt werden, kann Attributliste weggelassen werden (Reihenfolge gemäß Schema):
INSERT INTO spielt_in
VALUES (‘Star Wars‘, 1977, ‘Alec Guinness‘);Auch per Anfrage möglich (dabei zunächst SELECT vollständig ausgeführt, dann INSERT | DISTINCT also notwendig):
INSERT INTO Studio(Name)
SELECT DISTINCT StudioName
FROM Film
WHERE StudioName NOT IN
(SELECT Name
FROM Studio);- fehlende Attribute verwenden Default-Wert aus Tabellendefinition oder sonst
NULL
Bulk insert
INSERT: zeilenbasiertes Einfügen aus SQL statements (SQL-Skript)IMPORT: zeilenbasiertes Einfügen aus Datei- Trigger und Nebenbedingungen bleiben aktiv
- Indizes werden laufend aktualisiert
LOAD: seitenbasiertes Einfügen aus Datei, am effizientesten- Trigger und Nebenbedingungen werden deaktiviert
- Indizes werden erst am Ende neu generiert
- variierende Syntax
Delete
DELETE FROM R WHERE ...- Lösche alle Tupel in , für die die Bedingung wahr ist
- auch ohne
WHEREmöglich, dann alle Tupel
DELETE FROM spielt_in
WHERE FilmTitel = ‘The Maltese Falcon‘
AND FilmJahr = 1942
AND Schauspieler = ‘Sydney Greenstreet‘;Update
UPDATE R SET ... WHERE ...SET-Klausel: kommaseparierte Wertzuweisungen
UPDATE Manager
SET Name = ‘Präs. ‘ || Name
WHERE ManagerID IN
(SELECT PräsidentID FROM Studios);Schemata (DDL)
- Data definition language
- Datentypen, Tabellen, Default-Werte, Indizes
Datentypen
CHAR(n): String fester LängeVARCHAR(n): String variabler Länge (maximal n)BIT(n): wieCHARfür bitsBIT VARYING(n): wieVARCHARfür bitsBOOLEANINTund VariantenFLOATund VariantenDECIMAL(n,d): n Stellen, d NachkommastellenCLOBundBLOB: character large object (lange Texte) | binary large object (Bilder, Videos, Songs)
Interne Datenspeicherung: Row-Store (Default: Tupel werden zeilenweise gespeichert) vs Column-Store Optimierung / Komprimierung
Tabellen
CREATE TABLE R ...DROP TABLE RALTER TABLE R ...ADDDROPMODIFY
- Default-Werte mit
DEFAULT
CREATE TABLE Schauspieler (
Name CHAR(30),
Adresse VARCHAR(255),
Geschlecht CHAR(1) DEFAULT ‚?‘,
Geburtstag DATE DEFAULT DATE ‚0000-00-00‘);ALTER TABLE Schauspieler
ADD Telefon CHAR(16) DEFAULT ‚unbekannt‘; -- ohne DEFAULT entstehen NULL-WerteConstraints und Trigger
-
PRIMARY KEY -
UNIQUE -
FOREIGN KEY ... PREFERENCES ... -
NOT NULL -
CHECK -
CREATE ASSERTION -
CREATE TRIGGER
Indizes
Erleichtert dem DBMS, Tupel mit einem bekannten Wert des Attributs zu finden (z.B. über Baumstruktur)
SELECT * FROM Film WHERE StudioName = ‘Disney‘ AND Jahr = ‘1990‘;- Variante 1: Alle 100.000 Tupel durchsuchen und
WHERE-Bedingung prüfen - Variante 2: Direkt alle 2000 Filme aus 1990 betrachten und auf
DisneyprüfenCREATE INDEX JahrIndex ON Film(Jahr);
- Variante 3: Direkt alle 100 Filme aus 1990 von ‘Disney’ holen
CREATE INDEX JahrStudioIndex ON Film(Jahr, Studioname);- Reihenfolge wichtig! (Anwendung später nur in dieser Reihenfolge möglich)
Löschen: DROP INDEX JahrIndex;
Indexwahl
- Index beschleunigt Punkt- und Bereichs-Anfragen sowie Joins erheblich
- Allerdings verlangsamt sich Einfügen, Löschen, Verändern der Tupel (Index muss aktualisiert werden)
- Indizes benötigen Speicherplatz
Komplexe Entscheidungen:
- Vorhersage der query workload und update-Frequenz
- Wahl der Attribute: Häufiger Vergleich mit Konstanten, häufiges Joinattribut
Vorüberlegungen:
- Hauptkosten einer Datenbank sind gelesene Diskblöcke
- Bei Punktanfragen mit Index statt aller Blöcke nur einen Block lesen
- Aber Index muss ebenfalls gespeichert und gelesen werden
- Update-Kosten bei Index sogar doppelt
Views
- Relationen aus
CREATE TABLE-Ausdrücken existieren tatsächlich (materialisiert, physisch) - Daten aus Sichten (views) existieren nur virtuell
- Sichten entsprechen Anfragen mit Namen
- wirken wie physische Relation
- Daten der Sicht ändern sich mit der Änderung der zugrundeliegenden Relation(en)
- Sichten können Zugriff auf Basisrelationen / private Attribute verhindern, aber dennoch beschränkten Zugriff für bestimmte Nutzer(gruppen) erlauben
- im Prinzip Unteranfragen
- Views können in Baumdarstellung der Anfragen schlicht “entfaltet” werden
- Views auch Schreibhilfe (z.B. beim Verjoinen)
- in einigen Fällen ist es möglich, Einfüge-, Lösch-, oder Updateoperationen auf Sichten durchzuführen
UPDATE-Operation muss auf zugrunde liegende Basisrelation übersetzt werden- nur bei einer Relation
- nur bei normalem
SELECT, keinDISTINCT, kein Selfjoin etc. - nur falls genug Attribute explizit verwendet werden, so dass alle anderen Attribute mit
NULLoder dem Default-Wert gefüllt werden können
CREATE VIEW ParamountFilme AS
SELECT Titel, Jahr
FROM Film
WHERE StudioName = 'Paramount';SELECT Titel
FROM ParamountFilme
WHERE Jahr = 1979;Hilfreich z.B. für Umbenennung von Attributen:
CREATE VIEW FilmeProduzenten(FilmTitel, Produzentenname) AS
SELECT Titel, Name
FROM Film, Manager
WHERE ProduzentID = ManagerID;
Tupelmigration
- Eine View verlangt eine
WHERE-Bedingung, die durch einUPDATEnicht mehr erfüllt wird (das Tupel migriert aus der Sicht heraus)
CREATE VIEW ReicheManager AS
SELECT Name, Gehalt, ManagerID
FROM Manager
WHERE Gehalt > 2000000;UPDATE ReicheManager SET Gehalt = 1500000
WHERE ManagerID = 25;Kann explizit verhindert werden:
CREATE VIEW ReicheManager AS
SELECT Name, Gehalt
FROM Manager
WHERE Gehalt > 2000000
WITH CHECK OPTION;Materialisierte Sichten
- viele Anfragen an eine Datenbank wiederholen sich häufig
- viele Anfragen sind Variationen mit gemeinsamem Kern
- Idee: Einmaliges Berechnen der Anfrage als Sicht (materialized view)
Wahl von Views zur Materialisierung:
- kostet Speicherplatz und Aktualisierungsaufwand
- abhängig von tatsächlichem Workload (wie bei Indizes)
Automatische Aktualisierung:
- bei Änderung der Basisrelationnen
- ggf. schwierig, z.B. bei Aggregaten, Joins, Outer-Joins etc.
- Algorithmen zur inkrementellen Aktualisierung
Automatische Verwendung von MVs:
- “Answering questions using views” automatisches Umschreiben der Anfragen notwendig
- hochkomplexes Optimierungsproblem
- Anfragen und Views variieren in Komplexität
- Algorithmen zur transparenten und kostenoptimalen Verwendung der materialisierten Sichten