Motivation & Syntax
XML-Elemente: Start-Tag, Ende-Tag, Elementinhalt
- z.B.
<vortragender> Ronald Bourret </vortragender> - leere Elemente:
<vortragender></vortragender/>oder kurz<vortragender/>(oder einfach weglassen)
Schachtelung:
<vortragender>
<name>Bourret</name>
<vorname>Ronald</vorname>
</vortragender>Klassifikation
Datenzentrierte Dokumente:
- strukturiert, regulär
- Beispiele: Produktkataloge, Bestellungen, Rechnung
Dokumentenzentrierte Dokumente:
- Unstrukturiert, irregulär, “mixed content” (Wert + Subelemente darin |
<span></span>in<p></p>zwischen Text) - Beispiele: wissenschaftliche Artikel, Bücher, E-Mails, Webseiten
Semistrukturierte Dokumente:
- Datenzentrierte und dokumentzentrierte Anteile
- Beispiele: Veröffentlichungen, Amazon
XML-Programmierung
DOM (Document Object Model):
- XLM-Dokumente intern als Bäume repräsentiert
- Unterschiedliche Knotentypen: Element, Attribut, etc.
- Methoden zum Traversieren und Manipulieren der Baumstruktur ( objekt-orientierte Sicht auf XML)
getParentNode() | getFirstChild() | getLastChild() | getChildren() | getPreviousSibling() | getNextSibling()- geben Knoten oder Listen von Knoten (keine Mengen) zurück, da XML-Elemente eine Reihenfolge haben
- verschiedenste Implementationen, Schnittstelle (API) aber vorgeschrieben
Schemata
- HTML ist XML mit bestimmten Schema analog für Datenbanken
- DTD (Document Type Definitions): Definieren die erlaubten Elemente, Attribute etc. (allerdings kein XML)
- z.B. optional durch
?, mehrfach möglich durch* - z.B.
<!ELEMENT hotel (name, kategorie?, adresse, hausbeschreibung, preise*)>
- z.B. optional durch
- XML-Schema: Selbst ein XML-Dokument (*.xsd), deutlich ausdrucksreicher als DTDs
- z.B. Attribut
minOccurs="0", auch Schlüssel oder Fremdschlüssel lassen sich ausdrücken (und entsprechend im Rahmen des Schemas überprüfen) - z.B.
<xs:element ref="fax" minOccurs="0"/>
- z.B. Attribut
Anfragesprachen
XPath
Idee: 5 Achsen decken alle Elemente ab
ancestoer / parentpreceding / preceding siblingfollowing / following siblingdescendant / childself+attribute+namespace(aktuelles Schema)
Syntax:

Beispiele:
# Gibt das Attribut 'Genre' aller Bücher aus
/bookstore/book/@genre
# Alle Bücher, die vom Autor 'Plato' stammen
/bookstore/book[author/name='Plato']
# Nachnamen aller Autoren, deren Vorname 'Herman' ist
//author[first-name='Herman']/last-name
# Preis für alle Bücher, die mind. einen Autor mit dem Vornamen 'Benjamin' haben
/bookstore/book[author/first-name='Benjamin']/price
# Titel aller Bücher, die den Begriff 'XML' im Titel enthalten
//book[contains(title, 'XML')]/titleXQuery
- basiert auf XPath
- ähnlich zu SQL
- Basiskonstrukt: FLWR-Ausdruck (
for / let,where,return| “richtige” Reihenfolge) - Ausdrücke werden aus anderen Ausdrücken zusammengesetzt (also Schachtelung möglich)
- Rückgabe ist immer wieder ein XML-Elemente
- Datenmodell ist geordneter Wald (flach, geordnet, nicht duplikatfrei keine (implizite) Mengensemantik)
<hotel name="Hotel Neptun">
<zimmertyp typ="EZ" preis="180" waehrung="DM"/>
<foto href="neptun01.jpeg"/>
</hotel>
<hotel name="Hotel Huebner">
<zimmertyp typ="EZ" preis="150" waehrung="DM"/>
<zimmertyp typ="DZ" preis="180" waehrung="DM"/>
</hotel>
<hotel name="Pension Draeger">
<foto href="bild-pd01.jpeg"/>
<foto href="bild-pd02.jpeg"/>
</hotel>Anfrage:
for $hotel in //hotel
return $hotel/fotoErgebnis:
<foto href="neptun01.jpeg"/>
<foto href="bild-pd01.jpeg"/>
<foto href="bild-pd02.jpeg"/>Erlaubt auch Konstruktion neuer XML-Elemente Anfrage:
<billighotels>
{ for $h in //hotel[zimmertyp/@preis <= 100]
return <hotel>
<name>{ $h/@name }</name>
{
for $z in $h/zimmertyp
where $z/@preis <= 100
return <preis>{ $z/@preis }</preis>
} </hotel>
</billighotels>Ergebnis:
<billighotels>
<hotel>
<name>...</name>
<preis>...</preis>
<preis>...</preis>
</hotel>
...
</billighotels>Speicherung von XML
SQL / XML
- stellt einen neuen Datentyp XML mit darauf operierenden Funktionen in Datenbank bereits
- Bestandteil des SQL-Standards (Standarderweiterung)
- definiert Abbildungen zwischen SQL und XML
- Anwendungfälle:
- Speicherung von XML-Dokumenten in der Datenbank als Wert des XML-Datentyps
- Generierung von XML-Dokumenten mittels SQL/XML-Funktionen
Modellbasierte Speicherung
Variante 1: Graph
- Verwendung von Relationen zur Speicherung von Elementen und Attributen
- XML-Elemente, -Attribute, etc. sind die Knoten des Graphen
- Schachtelung der Elemente sind die Kanten
- Elemente (ID, Elementname, Verweis auf Vorgänger, Ordnung, Wert)
- Attribute (ID, Attributname, Verweis auf Element, Wert)
- Knoten erhalten (intern) eine ID durch Traversierung des Graphen
Anfragen:
- Angepasstes SQL, durch Datenbankschema bestimmt
- Viele Selfjoins (bei komplexeren Anfragen)
-- Hotels in Warnemünde
SELECT a.wert
FROM Elements a, Elements b
WHERE a.element = 'hotelname'
AND b.element = 'ort'
AND b.wert = 'Warnemünde'
AND a.DocID = b.DocIDVariante 2: Speicherung des DOM
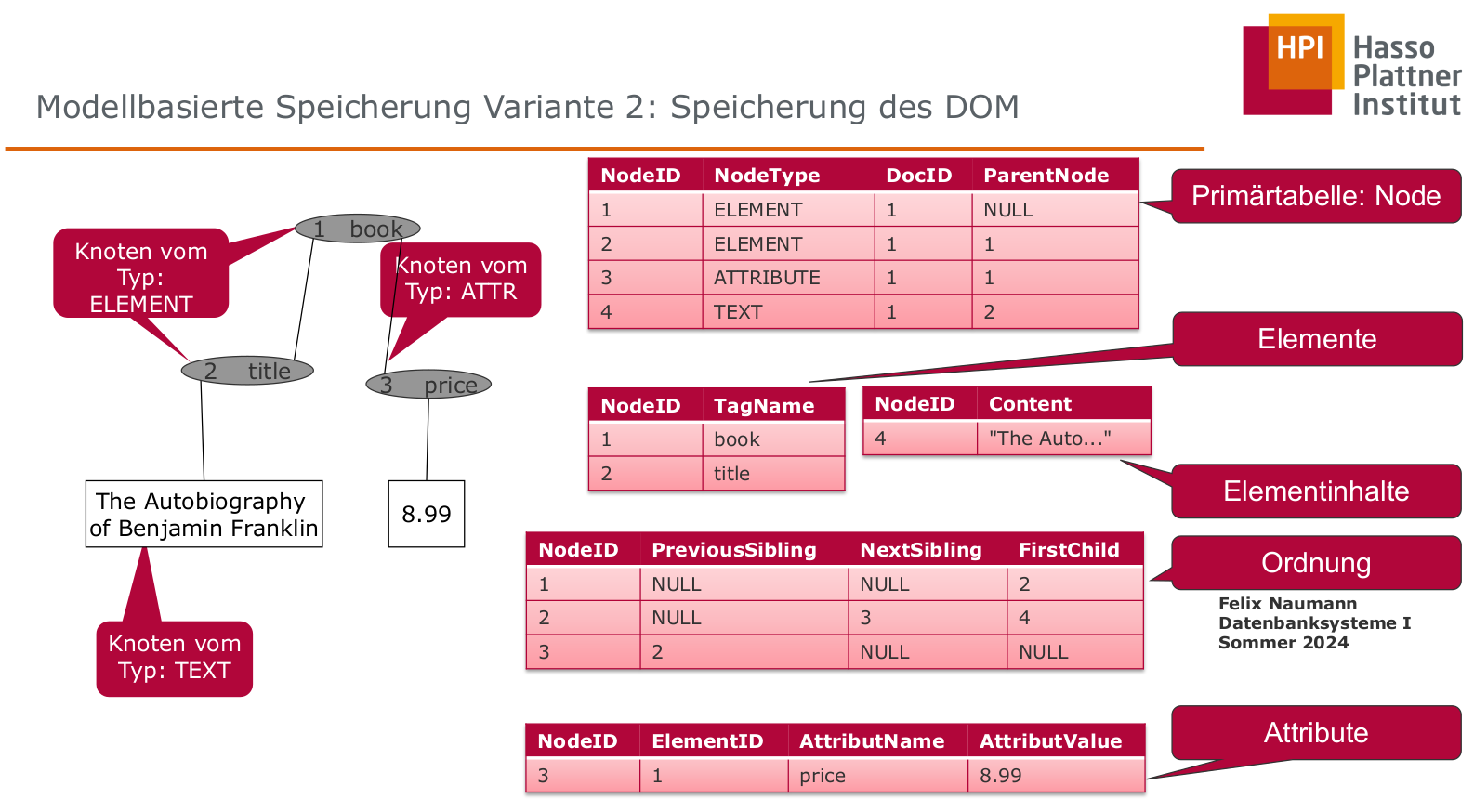
Struktur-basierte Verfahren: Abbildung von XML auf relationale Datenbank
- Jeder Elementtyp wird auf eine eigene Relation abgebildet
- benötigt festes Schema (DTD / XML-Schema)
- Anfragen verwenden SQL-Funktionalität
- RDBMS-Datentypen werden verwendet
- Abbildung von Kollektionstypen durch Aufteilung auf zusätzliche Relationen
Variante 1:
- Alle Möglichkeiten in einer Tabelle viele Nullwerte, implizite Bedeutung einer Zeile
Variante 2:
- Aufspaltung auf mehrere Tabellen
- Bei Anfragen Vereinigung der Tabellen zur Zusammenführung nötig
Variante 3:
- (text-basiert) – Verwendung einer Spalte vom Typ XML
- XML-Typ bietet native Methoden zum Zugriff: XQuery-Anfrage